An einem unserer Entwicklungssysteme nutzte ich bisher zwei 24 Zoll IPS-Schirme mit einer Auflösung von 1920×1200. Vor einigen Monaten hatte ich zudem meine alte Nvidia GTX 460 Grafikkarte gegen eine GTX 750 TI von Gigabyte ausgetauscht. Letztere bietet aus meiner Sicht einen annehmbaren Kompromiss zwischen 2D/3D-Leistung und Preis – zumal ich kein Interesse an PC-Spielen habe. Die Umstellung ging problemlos – soweit man mal von kleineren Problemen der proprietären Nvidia-Treiber in der aktuellen KDE 4.14 / KDE 5 Umgebung absieht (siehe die Off Topic Anmerkungen am Ende des Artikels).
Nachfolgend möchte ich darstellen, dass und wie man diese Konfiguration unter Linux um einen DELL U2515H in dessen nativer Auflösung erweitern kann. Insgesamt ergibt sich damit ein Linux-System (in meinem Fall unter Opensuse 13.2 und KDE) mit 3 Schirmen und einer (virtuellen Xinerama) Screenbreite von 6400 Pixeln.
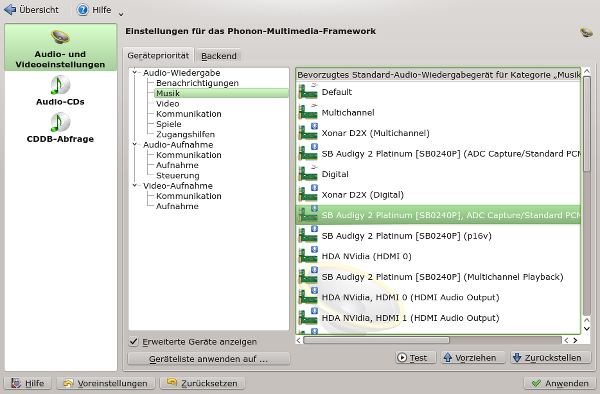
Verfügbare Schnittstellen der Gigabyte GTX750 GTI
Gigabytes GTX 750 TI hat 2 DVI- und 2 HDMI-Schnittstellen, aber leider keinen Display Port. 4K Auflösung wird auch nur in Spezialkonfigurationen unterstützt – die Schirme müssen hierzu einen bestimmten Modus mitmachen. Eine Auflösung von 2560×1440 bringt die Karte laut Spezifikation aber sehr wohl zustande – zumindest an einem Schirm. Über das Fehlen einer Display-Port Schnittstelle hatte ich beim Kauf nicht weiter nachgedacht. Da immer mehr Schirme jedoch keine DVI-Schnittstelle mehr anbieten, ist das ein Punkt, der künftig meine Graka-Entscheidungen sehr viel stärker beeinflussen wird.
25 Zoll Schirm Dell U2515H
Jetzt hat einer meiner älteren Schirme – ein von mir geliebter alter Samsung 244T mit S-PVA Panel (Samsung hat danach nie wieder so gute Monitore gebaut!) – eine Macke: Der Schirm kommt nach einer längeren Abschalt-Phase durch KDE’s Powersaving Funktionen u.U. nicht mehr hoch. Wir hatten solche Probleme schon früher – vermutete Ursache sind defekte oder altersmüde Kondensatoren der Schalt-Elektronik des Schirms. Das Panel selbst ist völlig OK. Zu anderen möglichen Ursachen s. die Off Topic Anmerkung weiter unten. Eine weitere Reparatur des Samsung lohnt sich jedenfalls nicht. Grund genug, über einen neuen Schirm für meinen Linux-Arbeitsplatz nachzudenken.
Die Wahl fiel nach Internet-Recherchen auf einen Dell U2515H. Dieser 25 Zoll (!) Schirm hat ein IPS AH Panel mit einer nativen Auflösung von 2560×1440 Pixeln und kostet z.Z. um die 300 Euro. Ich habe mir den Schirm bei einem netten Händler (Schwanthaler-Computer) gegen einen Aufpreis vorführen lassen und war recht angetan. Ein paar Stichpunkte:
Der hohe Kontrast der Standardeinstellung ist mir persönlich zu intensiv – aber das kann man sehr gut manuell nachregeln – ebenso wie die Helligkeit. Die Winkelabhängigkeit von Helligkeit, Farbtreue, Kontrast des Bildes halten sich in den Grenzen dessen, was man von einem besseren IPS-Panel erwarten kann. (Mit der Qualität eines PVA oder MVA Panels kann sich ein IPS Schirm in diesem Punkt von Haus aus nicht messen.) Ja – es gibt auch einen typischen IPS Glow – in vertikaler Richtung ausgeprägter als in horizontaler – besonders wenn man von unten nach oben auf den Schirm sieht. Es ist ein flächiger, weißlicher Effekt – er führt aber interessanterweise nicht zu Farbverfälschungen, wie ich sie schon bei anderen Schirmen gesehen habe. Der Effekt ist subjektiv geringer und auch homogener als bei einem ASUS 248PBQ.
Die Entspiegelung des U2515H hätte für meine Gefühl besser sein können; eine helle Tischplatte oder ein eigenes weißes Hemd wird im Schirm etwas verwaschen wahrnehmbar sein. Die Entspiegelung ist geringer als bei aktuellen ASUS Schirmen. Aber das ist vielleicht Geschmackssache und nicht jeder mag die Körnigkeit stark entspiegelter Schirme. Die Homogenität der Ausleuchtung ist zumindest bei meinem Exemplar recht gut; da habe ich im Netz schon anderes gelesen. Subjektiv meine ich, einen minimalen Helligkeitsabfall zu den Rändern links und rechts feststellen zu können – hier schlägt vielleicht aber auch schon die Winkelabhängigkeit des Bildes in Kombination mit der Breite des Schirms zu.
An die Bedienlogik und die Touch-Tasten konnte ich mich relativ schnell gewöhnen. Die manuelle Farbregelung ist für mein Gefühl zu sensibel – hier schlagen nichtlineare Effekte schnell zu – aber es ist durchaus möglich, die Farbeinstellungen manuell allein über die Steuerungsfunktionen des Schirms selbst anzupassen. (Eine echte Kalibrierung ersetzt das nicht). Schlechter als bei aktuellen Asus-Schirmen im Bereich zwischen 300 und 500 Euro ist die manuelle Bild-Regelung des Dell in keinem Fall – eher besser. Zudem bietet Nvidias Applikation “Nvidia X server Settings” für Linux die Möglichkeit pro Schirm individuelle Einstellungen der Farbkanäle vorzunehmen. Ein Manko des DELL : Eine stufenlose Gamma-Regelung ist leider nicht möglich. Hier muss man auf Möglichkeiten der Grafikkarte zurückgreifen.
Relativ beeindruckend ist die Darstellung von Grauverläufen in Testbildern. Ich konnte bei normalem Kontrast bislang keinerlei Streifigkeit erkennen. Bzgl. Spielen habe ich nur Alien Arena in verschiedenen Auflösungen angesehen. Kein akutes Problem erkennbar. Ich habe aber keine Ansprüche und spiele aus Zeitmangel so gut wie nie. Videos: Von meiner Seite kein Problem erkennbar.
Ausführliche Review-Berichte zum U2515H von professionellen Testern findet man z.B. hier:
http://www.tftcentral.co.uk/ reviews/ dell_u2515h.htm
http://www.prad.de/ new/ monitore/ test/ 2015/ test-dell-u2515h-teil10.html
Kein DVI-Anschluss für den Dell U2515H – funktioniert HDMI mit einer Auflösung von 2560×1440?
Das größte Problem stellte für mich bei der Kaufentscheidung die hohe Auflösung in Kombination mit der Tatsache dar, dass der DELL U2515H nur HDMI und Display-Port-Anschlüsse, aber keinen DVI-Eingang besitzt. Im Internet hatte ich vorab über erhebliche Probleme anderer Leute gelesen, die hohe Auflösung von 2560×1440 bei diesem und vergleichbaren Schirmen über HDMI (gem. 1.4 Standard) überhaupt zum Laufen zu bringen – und das an Arbeitsplätzen mit nur einem Schirm. Wenn überhaupt, so klappte das meist nur mit reduzierter Bildwiederholrate von 55 Hz oder gar nur 30 Hz – unter Linux wie unter MS Win. Weniger Probleme hatten Anwender dagegen bei Verwendung eines Displayports – aber genau einen solchen Anschluss bietet nun die Gigabyte GTX 750 TI nicht. Da sah ich doch ein erhebliches Risiko auf mich zukommen.
Dell 2515H parallel mit zwei 1920×1200 Karten an der GTX 750 TI unter Linux?
Meine Ansprüche waren aber noch höher: Ich wollte den Schirm in nativer Auflösung und in Kombination mit mindestens einem, besser aber zwei 1920×1200 Schirmen an der GTX 750 TI zum Laufen unter Linux bringen. Die gute Nachricht ist: Ja, das geht ! Voraussetzungen sind:
- Ein gutes HDMI Kabel. Ich habe mir ein ca. 13 Euro teures Delock Kabel geleistet, das gem. Spezifikation u.a. Übertragungsraten von bis zu 10,2 Gb/s und Auflösungen bis zu 4096×2160 px unterstützen soll.
- Der Einsatz des proprietären Nvidia-Treibers >= NVIDIA-Linux-x86_64-346.47
- Etwas Experimentierwillen und der Einsatz des proprietären Nvidia-Treibers. (Ich sollte besser sagen: Mit dem proprietären Treiber geht es sicher. Mit dem nouveau-Treiber habe ich es bisher schlicht nicht getestet. Es mag damit ggf. auch funktionieren.)
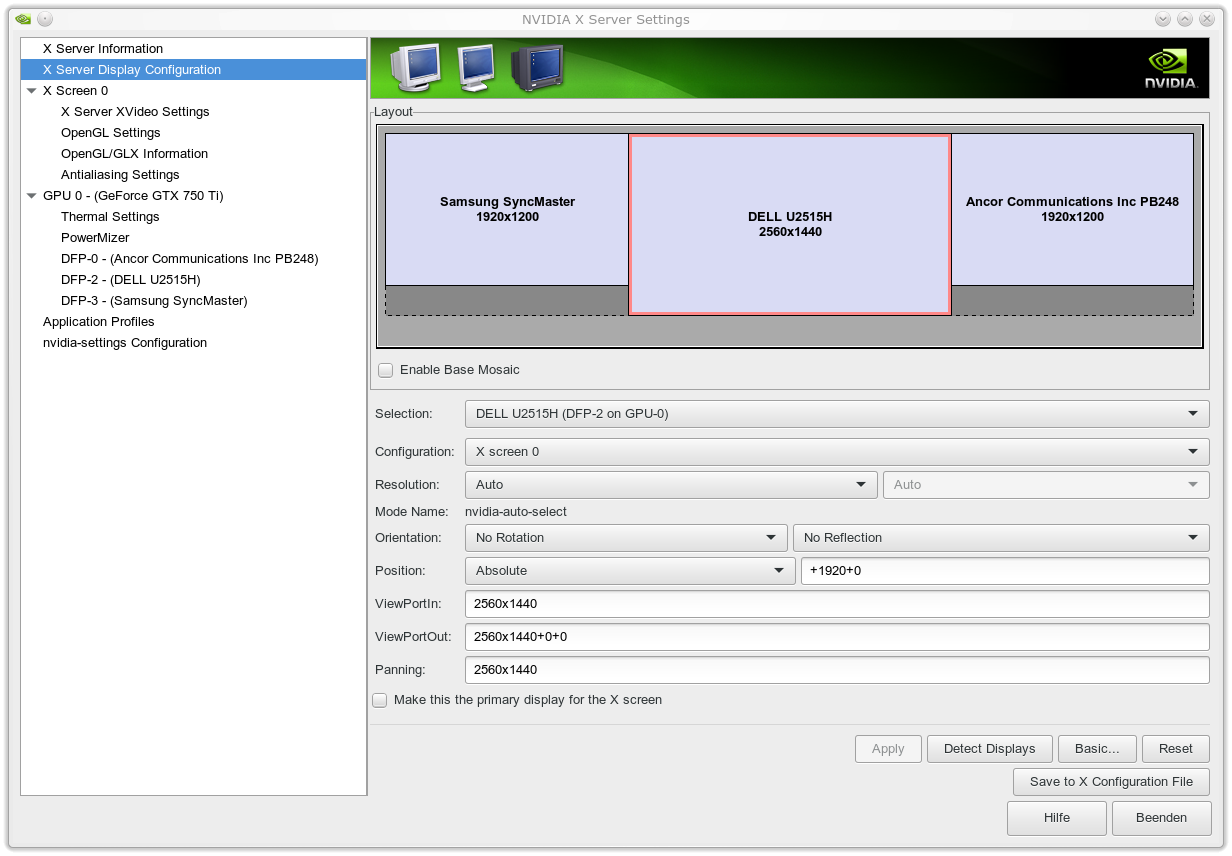
Mein erster Versuch, auch nur einen weiteren Schirm zusammen mit dem DELL U2515H zum Laufen zu bringen, scheiterten allerdings. Ich nutzte und nutze zur Grundeinstellung Nvidias “NVIDIA X SERVER Settings”-Applikation und dort den Punkt “X Server Display Configuration”.
Ich schaffte es im ersten Anlauf einfach nicht, den Dell 2515H an der ersten HDMI Schnittstelle der Graka in Kombination mit einem ASUS PB248Q am ersten DVI-Anschluss so zum Laufen zu bringen, dass ich die Maximalauflösung am Dell bei 60 Hz erhalten hätte. Möglich waren nur Auflösungen von 2048×1152 oder 1920×1200. Die höchste Auflösung 2560×1440 wurde in der “Nvidia X Server Settings”-Applikation (unter KDE) gar nicht angeboten. Auch die Einstellmöglichkeiten unter den
“KDE Systemeinstellungen >> Hardware >> Anzeige und Monitor”
boten die maximale Auflösung nicht an. Ich kann nur sagen: Lasst euch dadurch nicht entmutigen. Was bei mir half, waren dann folgende Schritte:
Raus aus KDE auf ein Konsolterminal >> init 3 >> Neuinstallation des proprietären Nvidia-Treibers bei angeschlossenem Dell-Schirm am ersten HDMI-Ausgang der Graka (und den beiden anderen 1920×1200 Monitoren an den 2 DVI-Ausgängen) >> Reboot >> Start KDE >> Nvidia-X-Server-Einstellung => – und siehe da: Die volle Auflösung wird seitdem angeboten.
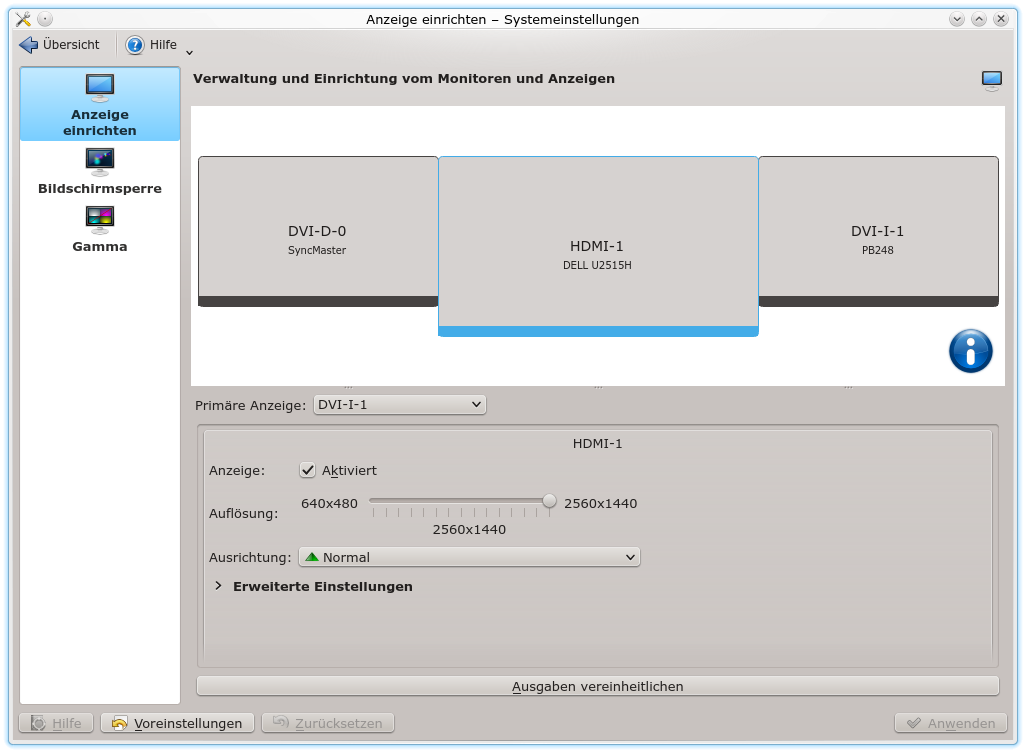
Auch unter KDE’s “systemsettings” wird die Maximalauflösung korrekt wiedergegeben:
Bilder
Im Moment sieht mein resultierendes physikalisches Screen-Layout wie folgt aus:
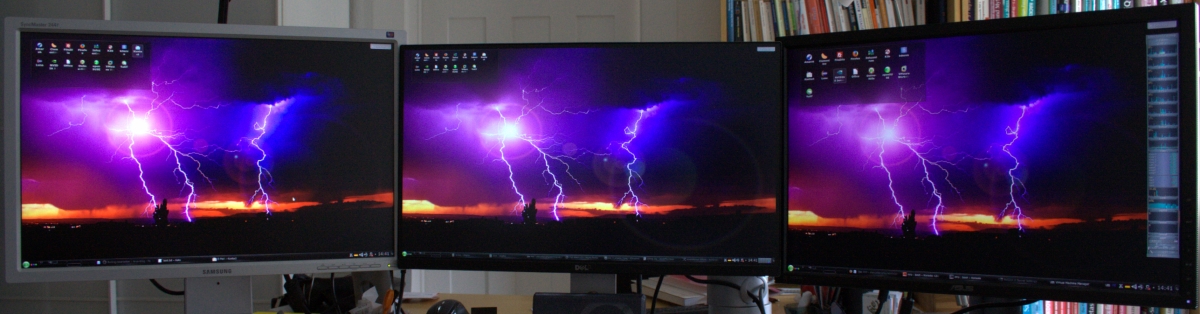
Das nachfolgende Bild stellt dagegen einen Screenshot – erzeugt mit Ksnapshot dar:

Dort bleibt links und rechts ein schwarzer Streifen am unteren Bildrand. Der findet sich auf den Schirmen selbst natürlich nicht (s.o.). Auf die Unterschiede in den bildlichen Darstellungen würde ich nicht zuviel geben – die Kamera sieht anders als das menschliche Auge und die Schirme sind unterschiedlich eingestellt. Subjektiv finde ich, dass der Dell kleine Farbnuancen und filigrane Bildstrukturen bei etwas heruntergeregeltem Kontrast sehr gut wiedergibt.
Simple xorg.conf
Die xorg.conf, die der proprietäre Nvidia-treiber erzeugt, hat folgenden Inhalt:
xorg.conf
# nvidia-xconfig: X
configuration file generated by nvidia-xconfig
# nvidia-xconfig: version 346.59 (buildmeister@swio-display-x86-rhel47-04) Tue Mar 31 14:42:07 PDT 2015
# nvidia-settings: X configuration file generated by nvidia-settings
# nvidia-settings: version 346.47 (buildmeister@swio-display-x86-rhel47-01) Thu Feb 19 19:18:25 PST 2015
Section "ServerLayout"
Identifier "Layout0"
Screen 0 "Screen0" 0 0
InputDevice "Keyboard0" "CoreKeyboard"
InputDevice "Mouse0" "CorePointer"
Option "Xinerama" "0"
EndSection
Section "Files"
EndSection
Section "InputDevice"
# generated from data in "/etc/sysconfig/mouse"
Identifier "Mouse0"
Driver "mouse"
Option "Protocol" "IMPS/2"
Option "Device" "/dev/input/mice"
Option "Emulate3Buttons" "yes"
Option "ZAxisMapping" "4 5"
EndSection
Section "InputDevice"
# generated from default
Identifier "Keyboard0"
Driver "kbd"
EndSection
Section "Monitor"
Identifier "Monitor0"
VendorName "Unknown"
ModelName "Ancor Communications Inc PB248"
HorizSync 30.0 - 83.0
VertRefresh 50.0 - 61.0
Option "DPMS" "false"
EndSection
Section "Device"
Identifier "Device0"
Driver "nvidia"
VendorName "NVIDIA Corporation"
BoardName "GeForce GTX 750 Ti"
EndSection
Section "Screen"
Identifier "Screen0"
Device "Device0"
Monitor "Monitor0"
DefaultDepth 24
Option "Stereo" "0"
Option "nvidiaXineramaInfoOrder" "DFP-0"
Option "metamodes" "DVI-I-1: 1920x1200_60 +0+0, DVI-D-0: 1920x1200_60 +1920+0"
Option "SLI" "Off"
Option "MultiGPU" "Off"
Option "BaseMosaic" "off"
SubSection "Display"
Depth 24
EndSubSection
EndSection
Der dort erscheinende Ancor Schirm – eigentlich ein ASUS PB248Q – ist der primäre Schirm; die anderen Schirme (Dell U5215, Samsung 244T) sind über die xinerama-Konfiguration in den nahtlosen “Screen0” mit einer Breite von 6400 px integriert.
Keine niedrige Taktung der Grafikkarte bei 3 Schirmen
Wenn jemand eine ähnliche Konfiguration mit drei Schirmen ausprobieren will, wird er schnell feststellen, dass die Grafikkarte auch bei Auswahl eines adaptiven Leistungsmodus nicht mehr in den Level 0 mit geringer Taktung zurückschaltet. Sie arbeitet immer im oberen Taktungsbereich für maximale Performance. Nachfolgend das Bild zum “Powermizer”-Eintrag des Nvidia-Tools:
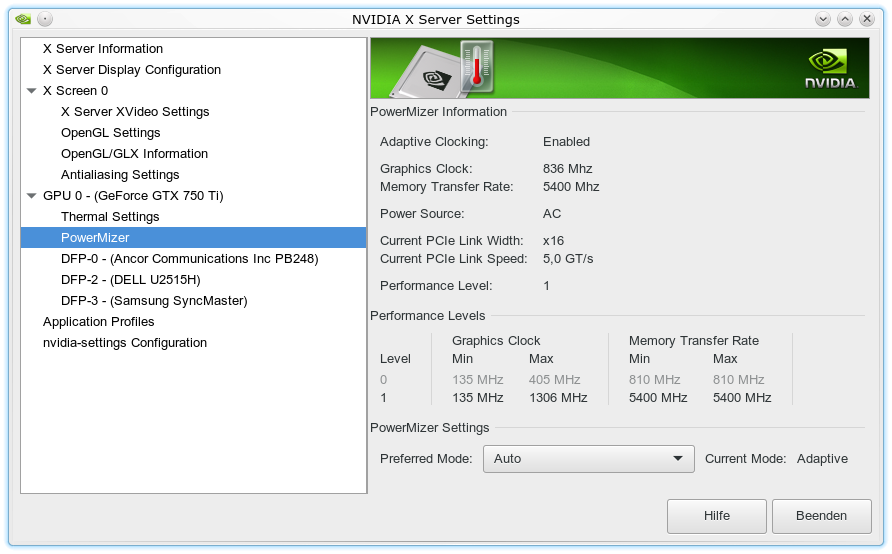
Dies ist bei zwei Schirmen noch anders. Da reicht eine geringere Leistungsfähigkeit. Woran immer der Nvidia-Treiber den Leistungsbedarf misst und welchen Grenzwert er dabei für die Höhertaktung beachtet. Die Lüfter-RPM steigt aber auch bei der höheren Taktung nur unwesentlich an. Im Office- und Entwicklungseinsatz, bei einer aktuellen Zimmertemperatur von ca. 26 Grad Celsius und geschlossenem Gehäuse liegen die GPU Temperatur bei ca. 41 Grad und die Lüfter RPM-Werten um die 1650 (Speed 33%).
Die hohe Auflösung des Dell U2515H – wo macht das was aus ?
Nun noch ein paar Worte zu den unterschiedlichen Auflösungen – besser zu der extrem hohen Auflösung des Dell
unter 25 Zoll. Das erste was hier zu sagen ist, ist dass ein 25 Zoll 16:9 Schirm in der Höhe etwa 1 cm kleiner ist als ein konventioneller 4:3 24 Zoll Schirm. In der Breite gewinnt man dagegen knapp 3.5 cm. In der physikalischen Ausdehnung fällt der Unterschied zu einem 4:3 24 Zoll Schirm also nicht sofort ins Auge (s. auch das Bilder zu den Schirmen oben). Demzufolge hat die doch deutlich höhere Auflösung bei gleicher Schrifteneinstellung spürbare Auswirkungen auf die Font-Darstellung. Das Bild ist gestochen scharf – aber die Schriften sind erwartungsgemäß deutlich kleiner als auf den 24 Zöllern mit 1920×1200. Nun sehe ich auf die Schirmdistanz auch in meinem Alter noch recht gut. Dennoch : Kleine Fonts sind anstrengender als große. Leider bietet KDE bisher keine Möglichkeit, Schriftfonts schirmspezifisch einzustellen. Wo kommt das beim Arbeiten unter Linux zum Tragen?
Auf der Desktop-Oberfläche kann man innerhalb der eingesetzten Plasmoide in vielen Fällen bzgl. Symbol- und Schriftgröße nachregeln. Kein Problem macht auch das Arbeiten mit Dokumenten oder dem Browser – hier kann man nahtlos und individuell skalieren.
Am meisten Probleme bereitet mir zur Zeit eher Eclipse. Unter Luna funktionieren die in
http://stackoverflow.com/ questions/ 6948374/ how-to-change-font-size-quickly-in-eclipse
angegebenen Tools für PDT nicht. Selbts wenn sie es täten – eine individuelle Font-Regelung pro geöffnetem Eclipse-Fenster gibt es zur Zeit leider genausowenig wie ein Reinzoomen in den Code eines Eclipse Fensters. Man muss also Schriftgrößen für die Code-Darstellung wählen, so dass man in den Eclipse-Fenstern, die am Dell angezeigt werden, noch gut lesen kann, auf den anderen Schirmen aber nicht zuviel Platz verliert. Mit 12-er Fonts kann ich im Moment ganz gut leben. Wirklich komfortabel ist das aber nicht. Der Request bzw. Bug zu Eclipse, in dem eine Editor- und Window-spezifische Zoom-Funktion gewünscht wird, hat nun leider schon einige Zeit am Buckel, ohne dass etwas Greifbares passiert wäre.
Nachtrag, 14.12.2015:
Die Nvidia GTX 750 TI funktioniert auch mit 2 Dell U2515H per HDMI und einem 1920×1200 Schirm per DVI. Siehe:
Linux – Nvidia GTX 750 TI – Parallelbetrieb von 2 Dell U2515H mit 2560×1440 plus einem 1920×1200 Schirm
Off Topic Anmerkung 1 – Nividia Treiber und Tearing
Ich habe auf allen unseren Opensuse-Systemen unter KDE immer wieder ein Problem mit den proprietären Drivern von Nvidia, die das Tearing der Kanten von schnell bewegten Fenstern betreffen nach dem KDE-Start. So erfordert eine tearing-freie Darstellung oftmals einen manuellen Switch in den OpenGL-Einstellung der KDE “systemsettings” (z.B. vom Raster-Modus auf Native oder auch von OpenGL 2.0 auf OpenGL 3.1). Den Einstellungswechsel man danach sofort wieder rückgängig machen. Es ist, als ob die Karte sich erst dann wirklich auf die vertikale Synchronisierungsfrequenz einstellt, obwohl das in den KDE-Einstellungen eigentlich bereits vorgegeben sein mag. Initial beim KDE-Start ist vollständige Tearing-Freiheit jedenfalls nicht für alle Typen von Fenstern gegeben. Zumindest nicht so, wie es ein (nachfolgender) manueller Einstellungswechsel bewirkt.
Ergänzung, 14.12.2015:
Der beschriebene Effekt liegt an einer unzureichenden Buffer-Konfiguration, die man über die xorg.conf beheben kann. Siehe:
Nvidia Treiber, KDE-Plasma-Desktop 4.14, Tearing-Effekt: Triple Buffering einschalten!
Off Topic Anmerkung 2 – Probleme mit Samsung T244 nach Screen Abschaltung durch KDE’s Energiesparfunktionen
Zwei unserer älteren Samsung 244T Schirme haben beim Einsatz an Linux-Systemen unter KDE bereits das Problem bekommen, dass sie eine Weile (ca. 1 Stunde) nach Abschaltung durch die KDE Stromsparfunktionen nicht mehr hochzubekommen sind. So flackert auch die Statusleuchte danach unkontrolliert. In der Phase bis dahin blinkt de Leuchte regulär. Einer der Schirme wurde daraufhin bereits zweimal repariert. Der Schirm, der das Problem aktuell wieder hat, ist nur nach längerem Abschalten, einem Reset und ein paar Tricks wieder zum Leben zu erwecken. Die Probleme liegen in der Schaltelektronik, nicht am Panel selbst. Es tritt übrigens nicht auf, wenn man den PC regulär runterfährt. Auch dann schaltet sich der Schirm ab – er schaltet sich dann aber beim Hochfahren des PCs auch wieder regulär an. Wegen des Alters und des Recovery nach längerer Abschaltzeit mag man natürlich an defekte Kondensatoren denken.
Ehrlich gesagt, glaube ich persönlich allerdings nicht, dass diese Probleme ausschließlich mit der Altersschwäche von Kondensatoren zu tun haben. Ich hege den Verdacht, dass hier auch eine fehlerhafte oder wiedersprüchliche Kombination eigener Stromsparfunktionen der Nvidia-Karten-Treiber mit Signalen der KDE-Stromsparfunktionen an Schirme, die nicht den aktuellen sondern älteren TCO-Normen gehorchen, verursacht werden. Diese Gefühl hängt mit folgenden Beobachtungen zusammen: Der Übergang von einem normalen Abschaltzustand des Schirms in einen unkontrollierten Zustand geschehen offenbar abrupt nach einem definierten Zeitintervall. Und ich habe ein System, an dem KDEs Screen Powersaving Funktionen nie aktiviert wurden – der dortige 244T hat null Probleme – obwohl er 1 Jahr älter als die anderen ist. Aber dass so eine Gefühl eine echte Grundlage hat, kann man nicht oder nur sehr schwer beweisen …
Der neue Dell tut jedenfalls bzgl. der Stromsparfunktionen genau das, was er soll.