This post and two following ones are about some simple iptables exercises concerning Linux virtual bridges. Linux bridges are typically used in virtualization environments. However, guest systems or even the host attached to a Linux bridge may become targets of “man in the middle” attacks. During such attacks the guests and the bridge may be manipulated to send packets to the “man in the middle” system and not directly to the intended communication partners. My objective is to get a clearer picture of iptables’ contributions to defense measures against such attacks.
Some “Howtos” on the Internet warn explicitly against using iptables at all on Linux bridges – especially not with active connection tracking. An example is the “libvirt wiki”: http://wiki.libvirt.org/page/Networking. Some of the warnings refer to an original discussion published here: http://patchwork.ozlabs.org/ patch/ 29319/
See also: https://bugzilla.redhat.com/ show_bug.cgi?id=512206
I think these concerns justify a closer look at iptables rules with respect to bridge ports. Comments are welcome.
Scenarios, limitations and objectives
In our test case we work with a KVM host with one bridge and later on also with two linked Linux bridges. In this first article we use one of the Linux guests on one of the bridges to initiate a “man in the middle attack” [MiM] against other guests of the very same bridge. The attacks are based on ARP spoofing and packet redirection. We then define some reasonable iptables rules with the intention to block the redirected traffic (to the MiM) and analyze the impact of these rules.
In a 2nd and 3rd article we extend the game to 2 bridges and the host attached to a port of one of the bridges.
Limitations and restrictions
It is obvious that we cannot prevent ARP-spoofing itself with iptables. iptables works on network layers 3/4, but not on layer 2 (Ethernet). iptables, therefore, does not allow for direct restrictions regarding the ARP protocol. So, the prevention of ARP packets with false MAC addresses, which typically initiate a MiM attack is not the objective of this article. It requires ebtables and/or arptables to block ARP spoofing at its roots. So, do not misunderstand me:
I do not and would not recommend to base any packet filter security across a Linux bridge on iptables alone. If you must use netfilter on bridges always combine iptables with basic ebtables/arptables rules – and test thoroughly against different kinds of attacks which try to break guest isolation. Always be aware of the fact that a bridge creates a global context in which packets must be inspected and followed precisely in their changing role as outgoing or incoming with respect to the bridge itself and its virtual interface ports. Global connection tracking on the TCP/IP level may be dangerous. If you give the bridge itself an IP – a situation which I do not at all like from a security perspective – take extra care. Things get even more complicated with multiple bridges on one and the same host.
Objectives
Nevertheless I think that one can learn something even from academic and unusual test configurations with iptables alone in place:
If we cannot prevent ARP spoofing itself by iptables – can we at least use iptables rules to deal with some consequences of ARP spoofing? More precisely:
Can we block the redirection of packets between ARP poisoned guests over the MiM system by means of IPtables alone? What relations of IP addresses and port devices have to be defined? And would a tool like FWbuilder support us reasonably enough with this task?
If so: How would we extend IPtables rules to situations
- where two Linux bridges are linked (by veth devices)
- or when segregated network parts with all guests belonging to the same logical IP segment are coupled via STP and border Ethernet interfaces of a central Linux bridge?
In both cases the spoofed communication may pass border NICs of a Linux bridge.
In this first article on the topic we look at one bridge alone with three guests. In the following posts we shall consider linked bridges.
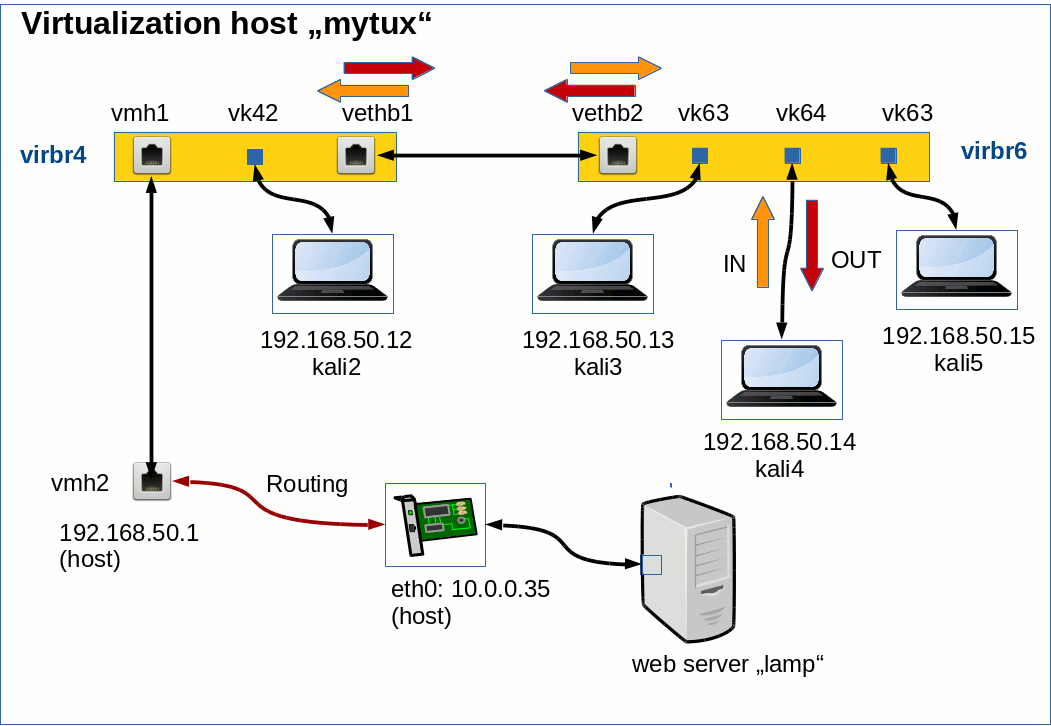
One bridge – 3 guests
Let us assume that we have 3 guests “kali3, kali4 and kali5” on a Linux bridge “virbr6”. The bridge device itself has no IP. The guest systems are attached to the bridge via standard tap device ports (vk63, vk64 and vk65, respectively). The virtual network can be created e.g. with the help of libvirt’s virt-manager. See article KVM/qemu, libvirt, virt-manager – persistent names for virtual network bridge ports of guest systems about how to set persistent names for the bridge sided end of “tap”-devices.
The corresponding Ethernet interfaces (eth0) of the guest operative systems – i.e. the guest side of the tap devices – are given the following IP addresses: 192.168.50.13 (eth0), 192.168.50.14 (eth0) and 192.168.50.15 (eth0), respectively.
How does the host see the bridge-ports?
mytux:~ # brctl showmacs virbr6
port no mac addr is local? ageing timer
1 52:54:00:8e:f2:d7 yes 0.00
2 5e:f4:32:30:f1:3a yes 0.00
2 aa:bf:ba:dc:52:31 no 1.35
3 fe:54:00:9f:5d:c1 yes 0.00
4 fe:54:00:74:60:4a yes 0.00
5 fe:54:00:0f:34:4f yes 0.00
5 ports instead of 3 ? Yeah, actually my virbr6 bridge is connected to another bridge (virbr4) by a veth pair. But we will ignore this connection most of the time ignore in this post. If you are interested in Linux bridge linking via “veth” devices see
Fun with veth devices, Linux virtual bridges, KVM, VMware – attach the host and connect bridges via veth
The veth pair explains the 2 MACs on port Nr. 2 of the bridge. A parallel look at the outcome of “ifconfig” or “ip link show” would show that port 3 actually corresponds to tap device “vk63”, port 4 corresponds to “vk64” and port 5 to “vk65”. And what about port 1? The Linux bridge itself could also work as an Ethernet device which could get an IP address on the host. We do not use this property here – nevertheless, there is an Ethernet port associated with the bridge itself.
How does the host see the (regular) IP-MAC relations so far? After pinging our 3 guests from the host we get:
mytux:~ # brctl showmacs virbr6
port no mac addr is local? ageing timer
1 52:54:00:8e:f2:d7 yes 0.00
2 5e:f4:32:30:f1:3a yes 0.00
2 aa:bf:ba:dc:52:31 no 1.35
3 fe:54:00:9f:5d:c1 yes 0.00
4 fe:54:00:74:60:4a yes 0.00
5 fe:54:00:0f:34:4f yes 0.00
mytux:~ # arp -n
Address HWtype HWaddress Flags Mask Iface
192.168.50.15 ether 52:54:00:0f:34:4f C vmh2
....
192.168.50.13 ether 52:54:00:9f:5d:c1 C vmh2
192.168.50.14 ether 52:54:00:74:60:4a C vmh2
We recognize our tap devices attached to the bridge. [By the way: vmh2 is a device that connects the host to one of the bridges (virbr4).]
Addendum 24.02.2016: Note a small, but decisive difference in the HW/MAC addresses
The first digit pair in the Ethernet address of the port device (i.e. the bridge sided end of the tap device) has a “fe“, whereas the Ethernet device of the Linux guest (i.e. the guest sided end of the tap device) has a “52“. The rest of the digits being the same. Logically, and also from the perspective of the bridge, these are 2 different (!) devices (though incorporated in one virtual tap). From the point of view of the bridge multiple MACs or even a new bridge may be located at the Ethernet segment behind a port.
Be aware of the fact that the so called “forward database” of a bridge [FDB], which relates MACs to ports, keeps track of the relation of our Linux guest MACs to their specific ports. Whereas the port MAC (with the leading “fe”) is permanently associated with the bridge, the MAC of the guest may disappear from the FDB after a timeout period, if no packets are received at the bridge from this guest MAC address.
In addition we make the following settings:
mytux:~ # brctl setageing virbr6 30
mytux:~ # brctl setageing virbr4 30
to be sure that the bridge works in a switch like mode and not as a hub.
Note that this defines a timeout period for the bridge’s FDB – i.e. after this period “stale” entries in the FDB of the bridge may be deleted. So the bridge may no longer know at which port the deleted MAC is located – and therefore temporarily flood all ports with packets. Therefore, bridge flooding is a situation we may need to cover with iptables-rules later on.
If you want to monitor changes of the bridges’ FDB or monitor general changes over all bridge links use the following commands:
bridge monitor all
and
bridge -statistics fdb show
The continuous output of the first command will show you directly when a stale MAC entry in the FDB is deleted. If you issue the second command twice with a reasonable time period in between you may search the output for missing or new MAC entries of guests.
Note further that we did not give the bridge itself any IP address! The bridge may therefore be called “transparent”. As “virbr6” has no IP address the guests (kali3 to 5) can not directly communicate with the host through the bridge itself as an Ethernet device. Just for information: In our scenario the host can only be reached indirectly over a transparently linked second bridge (virbr4) and a further veth pair there which leads to an external Ethernet device with address 192.168.50.1.
ICMP packages and regular pinging – what do we allow?
First we shall have a look at ICMP packages, only. Our basic policy with iptables is that we deny everything that is not explicitly allowed. Regarding further rules we should be aware of the following:
When setting up iptables rules on bridges we must be precise and specific with respect to the packet direction across the involved bridge port interfaces.
Note: It is the perspective of the bridge and NOT the perspective of the guest that counts.
I always use a 3D picture to be sure: Assume the bridge and its ports to be located above the guests. Then a packet going up is incoming, a packet moving downwards is outgoing.
Let us assume you want to ping from kali3 to kali5. From the point of view of the bridge there are 2 packet directions involved: We first get an incoming ICMP (type 8) packet via bridge interface “vk63”, which then is directed (or “forwarded”) outwards through “vk65”. To allow for the pinging we would need rules of the logical form
bridge vibr6 rule : src 192.168.50.13, dest 192.168.50.15 – ICMP in via vk31, out
via vk65 => ALLOW
and analogously for the other guests and interfaces. Actually this rule may be split up into 2 subsequent rules:
bridge vibr6 rule : src 192.168.50.13, dest 192.168.50.15 - ICMP in via vk31 => ALLOW
bridge vibr6 rule : src 192.168.50.13, dest 192.168.50.15 - ICMP out via vk65 => ALLOW
which are to be considered in the basic chains of iptables. This leads us to the next question: Which of the iptables chains is relevant here?
In our example it is the FORWARD chain. For the interaction of netfilter components (ebtables/iptables) in kernels with activated netfilter see the following link: http://ebtables.netfilter.org/ br_fw_ia/ br_fw_ia.html
That we need to set up FORWARD rules is also logical as the bridge does nothing else than forwarding packets between its ports and thus transfers the packets to attached destination guests or into segregated network parts behind some of the ports (with the “spanning tree protocol” STP set to ON).
ARP spoofing and the bridge
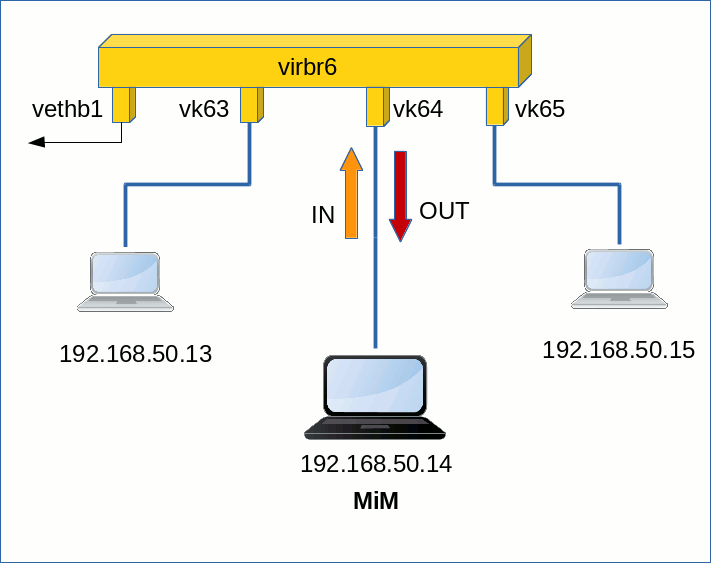
Consider a situation in which guest “kali4” acts as a “man in the middle”, who wants to sniff or even manipulate the traffic (e.g. for “secrets”) between kali3 and kali5. A user with root rights on kali4 would use a ARP spoofing tool like “dsniff” to (arp-) poison its neighbouring guests via the following command sequence:
root@kali4: ~# echo 1 > /proc/sys/net/ipv4/ip_forward
root@kali4: ~# iptables -A OUTPUT -p icmp --icmp-type redirect -j REJECT
root@kali4: ~# arpspoof -i eth0 -t 192.168.50.13 192.168.50.15 & 2> /dev/null
root@kali4: ~# arpspoof -i eth0 -t 192.168.50.15 192.168.50.13 & 2> /dev/null
The first command guarantees that redirected and sniffed packets are forwarded (routed) via the MiM system (kali4) to their original targets. The second command on the MiM-system avoids sporadic ICMP “redirect” answers to the poisoned and pinging guests – such answers would/could indicate to these guests that something is wrong. The 3rd and the 4th command eventually poison the internal ARP caching tables of the guests. I.e., these commands spoil the cached information on IP-MAC relations after some time.
Let us look at kali3 – before the attack:

And during the attack:

In a previous post of this blog we saw that a Linux bridge learns about the relation of MAC addresses and bridge ports – and thus pins a specific communication down to just the 2 involved ports of a specific communication (basic guest isolation). The bridge normally does not spread communication packets over all ports (at least with a setageing parameter > 0).
Note that this does not help to prevent MiM attacks. As the bridge itself works on layer 2 it ignores IP-MAC relations during packet forwarding. (It may learn about IP-MAC relations only through the ARP protocol.) The bridge furthermore does not know whether routing may occur somewhere. And the guests themselves cannot ignore that situations where several IP addresses may be associated with one and the same MAC are possible. Because of all these reasons Ethernet packets are inevitably sent and forwarded across the bridge were the guests think they should be sent to – according to their own internal ARP tables, which are poisoned during the attack.
Therefore after ARP spoofing the bridge would receive 2 subsequent ping request packets from kali3 and from kali4 with the logical route
src 192.168.50.13, dest 192.168.50.15 - ICMP ping request in via vk63, out via vk64
src 192.168.50.13, dest 192.168.50.15 - ICMP ping request in via vk64, out via vk65
And the ping answers back via
src 192.168.50.15, dest 192.168.50.13 - ICMP ping answer in via vk65, out via vk64
src 192.168.50.15, dest 192.168.50.13 - ICMP ping answer in via vk64, out via vk63
A small side aspect: I should mention that despite the switch-like operational mode of the Linux bridge, I sometimes – very rarely – saw that even the KVM host reacted towards the ARP poisoning and showed some wrong entries in its internal ARP cache table – some time after the attack started. I have not clarified, yet, what the reason for this change of the hosts ARP table actually is. If some reader knows the reason please write me a mail. I suspect gratuitous packets, or (more likely) some rare hub like flooding situation on the bridge, but …
E.g. after a restart of all virtual machines, the begin of the ARP poisoning and after pinging the host continuously from the MiM system for a while, you may eventually find the following ARP table change on the KVM host:
mytux:~ # arp
Address HWtype HWaddress Flags Mask Iface
192.168.50.15 ether 52:54:00:0f:34:4f C vmh2
192.168.50.13 ether 52:54:00:9f:5d:c1 C vmh2
192.168.50.14 ether 52:54:00:74:60:4a C vmh2
mytux::~ # arp
Address HWtype HWaddress Flags Mask Iface
192.168.50.15 ether 52:54:00:74:60:4a C vmh2
192.168.50.13 ether 52:54:00:74:60:4a C vmh2
192.168.50.14 ether 52:54:00:74:60:4a C vmh2
And the port-MAC-association? It remains as it was:
mytux:~ # brctl showmacs virbr6
port no mac addr is local? ageing timer
...
5 fe:54:00:0f:34:4f yes 0.00
4 fe:54:00:74:60:4a yes 0.00
3 fe:54:00:9f:5d:c1 yes 0.00
Be aware, however, of the fact that this information tells us nothing about the present state of the FDB table of the bridge! Actually, due to our “setageing” parameter certain MAC addresses of guests may drop out of the forward list of the bridge, if the guests are inactive with respect to network communication, and this in turn may result in a subsequent (temporary) bridge port flooding.
So, if you stop the ARP poisoning, reset the ARP tables and start the spoofing again, an ARP poisoning of the host itself it may not happen directly. It may, however, happen after some time. (By the way: Any direct pinging from the host to the guests will correct the ARP table to the real values again – at least for some time.)
Anyway and whatever the precise reason – it is interesting that there obviously are circumstances under which the local poisoning of bridge guests may impact even the ARP table on the bridge’s host itself. On the defense side this may give us a secondary chance (besides monitoring the violation of iptables and ebtables rules) to detect ARP spoofing attacks: by monitoring the host’s internal ARP table and analyzing its contents for implausible changes.
iptables rules to prevent misguided packets
To avoid part of the redirected packet transport across the Linux bridge we would require a rule of the logical form
bridge vibr6 rule : src any, dest 192.168.50.15 - in any, out via vk64 => DENY
We can reformulate the rule with a negation (!) in a more general way:
bridge vibr6 rule : src any, !dest 192.168.50.14 - in any, out via vk64 => DENY
In addition it is reasonable to forbid packets which (seem to) come from kali3 and are “outbound” to kali3:
bridge vibr6 rule : src 192.168.50.13, dest any - in any, out via vk63 => DENY
Also incoming packets via vk63 from sources not being kali3 make no sense:
bridge vibr6 rule : ! src 192.168.50.13, dest any - in vk63, out any => DENY
Actually, on our bridge we would have to cover analogous variants of all of the above DENY rules for all other guest ports and protocols.
Note that all these rules define fixed relations between each of the defined bridge ports, an associated IP and certain packet directions across the port: with iptables alone we are restricted to such types of relations.
Graphical help – FWbuilder
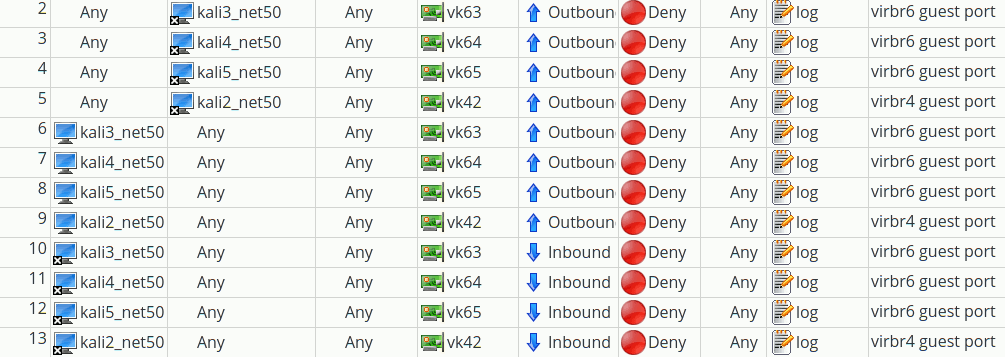
A problem with the relations above is that they are potentially many – depending at least quadratically on the number of guests on a bridge. An efficient administration requires either a tool or good scripting experience or both. A tool like FWbuilder at least supports us graphically:
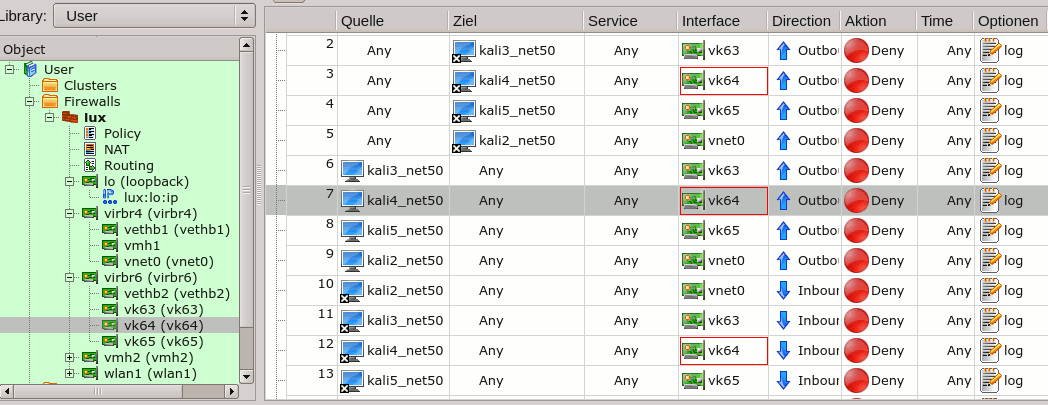
The rules created for the shown conditions look like:
#
# Rule 2 (vk63)
#
echo "Rule 2 (vk63)"
#
$IPTABLES -N Out_RULE_2
$IPTABLES -A FORWARD -m physdev --physdev-is-bridged --physdev-out vk63 ! -d 192.168.50.13 -j Out_RULE_2
$IPTABLES -A Out_RULE_2 -j LOG --log-level info --log-prefix "RULE 2 -- DENY "
$IPTABLES -A Out_RULE_2 -j DROP
#
# Rule 3 (vk64)
#
echo "Rule 3 (vk64)"
#
$IPTABLES -N Out_RULE_3
$IPTABLES -A FORWARD -m physdev --physdev-is-bridged --physdev-out vk64 ! -d 192.168.50.14 -j Out_RULE_3
$IPTABLES -A Out_RULE_3 -j LOG --log-level info --log-prefix "RULE 3 -- DENY "
$IPTABLES -A Out_RULE_3 -j DROP
#
# Rule 4 (vk65)
#
echo "Rule 4 (vk65)"
#
$IPTABLES -N Out_RULE_4
$IPTABLES -A FORWARD -m physdev --physdev-is-bridged --physdev-out vk65 ! -d 192.168.50.15 -j Out_RULE_4
$IPTABLES -A Out_RULE_4 -j LOG --log-level info --log-prefix "RULE 4 -- DENY "
$IPTABLES -A Out_RULE_4 -j DROP
#
.....
.....
# Rule 6 (vk63)
#
echo "Rule 6 (vk63)"
#
$IPTABLES -N Out_RULE_6
$IPTABLES -A FORWARD -m physdev --physdev-is-bridged --physdev-out vk63 -s 192.168.50.13 -j Out_RULE_6
$IPTABLES -A Out_RULE_6 -j LOG --log-level info --log-prefix "RULE 6 -- DENY "
$IPTABLES -A Out_RULE_6 -j DROP
#
# Rule 7 (vk64)
#
echo "Rule 7 (vk64)"
#
$IPTABLES -N Out_RULE_7
$IPTABLES -A FORWARD -m physdev --physdev-is-bridged --physdev-out vk64 -s 192.168.50.14 -j Out_RULE_7
$IPTABLES -A Out_RULE_7 -j LOG --log-level info --log-prefix "RULE 7 -- DENY "
$IPTABLES -A Out_RULE_7 -j DROP
#
# Rule 8 (vk65)
#
echo "Rule 8 (vk65)"
#
$IPTABLES -N Out_RULE_8
$IPTABLES -A FORWARD -m physdev --physdev-is-bridged --physdev-out vk65 -s 192.168.50.15 -j Out_RULE_8
$IPTABLES -A Out_RULE_8 -j LOG --log-level info --log-prefix "RULE 8 -- DENY "
$IPTABLES -A Out_RULE_8 -j DROP
#
....
....
#
# Rule 11 (vk63)
#
echo "Rule 11 (vk63)"
#
$IPTABLES -N In_RULE_11
$IPTABLES -A INPUT -m physdev --physdev-in vk63 ! -s 192.168.50.13 -j In_RULE_11
$IPTABLES -A FORWARD -m physdev --physdev-in vk63 ! -s 192.168.50.13 -j In_RULE_11
$IPTABLES -A In_RULE_11 -j LOG --log-level info --log-prefix "RULE 11 -- DENY "
$IPTABLES -A In_RULE_11 -j DROP
#
# Rule 12 (vk64)
#
echo "Rule 12 (vk64)"
#
$IPTABLES -N In_RULE_12
$IPTABLES -A INPUT -m physdev --physdev-in vk64 ! -s 192.168.50.14 -j In_RULE_12
$IPTABLES -A FORWARD -m physdev --physdev-in vk64 ! -s 192.168.50.14 -j In_RULE_12
$IPTABLES -A In_RULE_12 -j LOG --log-level info --log-prefix "RULE 12 -- DENY "
$IPTABLES -A In_RULE_12 -j DROP
#
# Rule 13 (vk65)
#
echo "Rule 13 (vk65)"
#
$IPTABLES -N In_RULE_13
$IPTABLES -A INPUT -m physdev --physdev-in vk65 ! -s 192.168.50.15 -j In_RULE_13
$IPTABLES -A FORWARD -m physdev --physdev-in vk65 ! -s 192.168.50.15 -j In_RULE_13
$IPTABLES -A In_RULE_13 -j LOG --log-level info --log-prefix "RULE 13 -- DENY "
$IPTABLES -A In_RULE_13 -j DROP
Ignoring some optimization potential, this is actually what we need. You see the clue:
FWbuilder knows about the bridge situation (see below) and creates rules with options
-m physdev –physdev-in/out device
The documentation from http://www.fwbuilder.org/ 4.0/docs/ users_guide5/ host-interface.shtml says accordingly:
Bridge port: This option is used for a port of a bridged firewall. The compilers skip bridge ports when they pick interfaces to attach policy and NAT rules to. For target firewall platforms that support bridging and require special configuration parameters to match bridged packets, compilers use this attribute to generate a proper configuration. For example, in case of iptables, the compiler uses -m physdev –physdev-in or -m physdev –physdev-out for bridge port interfaces. (This object applies to firewall objects only.)
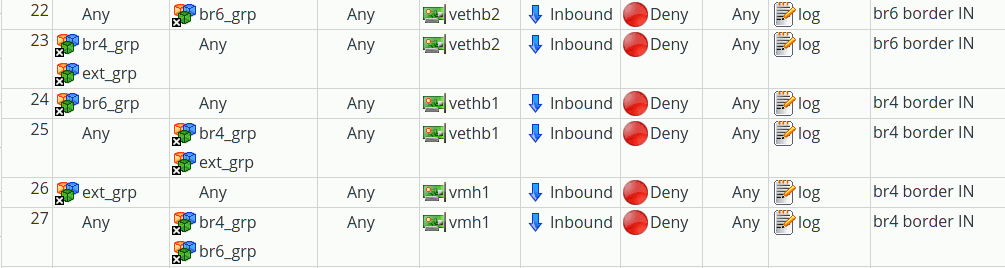
It requires, however, a special configuration of FWbuilder with respect to the defined interfaces and the bridges on the firewall system – i.e. the virtualization host in our test situation:
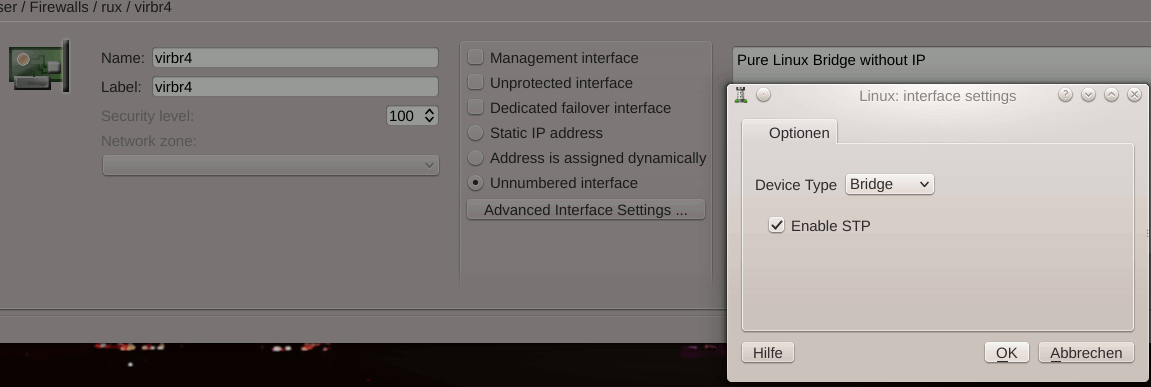
The same of course for bridge “virbr6”.
Note that our rules (produced by FWbuilder above) for the bridge ports vk63, vk64, vk65 would also work in case of a port flooding situation – if they are not circumvented by other leading rules. The latter being a point we shall come back to.
What packets do we allow?
On a firewall with a basic drop policies we need, of course, to define acceptance conditions for packets, too. Without going into details we need logical rules like:
bridge vibr6 rule : src 192.168.50.13, dest 192.168.50.15, 192.168.50.14, any ICMP - in via vk31 => ALLOW
An example is shown here:

# Rule 21 (vk63)
#
echo "Rule 21 (vk63)"
#
$IPTABLES -N In_RULE_21
$IPTABLES -A FORWARD -m physdev --physdev-in vk63 -p icmp -m icmp -s 192.168.50.13 -d 192.168.50.1 --icmp-type any -m state --state NEW -j In_RULE_21
$IPTABLES -A INPUT -m physdev --physdev-in vk63 -p icmp -m icmp -s 192.168.50.13 -d 192.168.50.1 --icmp-type any -m state --state NEW -j In_RULE_21
$IPTABLES -N Cid8093X19506.0
$IPTABLES -A FORWARD -m physdev --physdev-in vk63 -p icmp -m icmp -s 192.168.50.13 --icmp-type any -m state --state NEW -j Cid8093X19506.0
$IPTABLES -A Cid8093X19506.0 -d 192.168.50.12 -j In_RULE_21
$IPTABLES -A Cid8093X19506.0 -d 192.168.50.14 -j In_RULE_21
$IPTABLES -A Cid8093X19506.0 -d 192.168.50.15 -j In_RULE_21
$IPTABLES -A In_RULE_21 -j LOG --log-level info --log-prefix "RULE 21 -- ACCEPT "
$IPTABLES -A In_RULE_21 -j ACCEPT
We need of course all variants for all the other bridge interfaces. To make life simpler you could define groups of recipients in a tool like FWbuilder.
Order of our rules
We eventually come to a trivial but important point: In which order must we arrange the discussed iptables DENY and ACCEPT commands? A little thinking shows:
We need the “DENY”-rules first before we allow anything else – i.e. we need the basic DENY rules discussed above as the leading rules in all affected chains!
If a packet is first allowed – e.g. due to some reasonable IN rule – then it definitely is allowed. To be on the safe side we, therefore, must probe the critical FORWARD rules for unacceptable outgoing and incoming packets over certain bridge ports, first.
A really critical aspect in the context is a potentially applied overall acceptance of packets for established connections (connection tracking). For most stateful inspection packet filters the general acceptance of incoming packets for established connections is a default.
E.g., in FWbuilder you have to turn this policy off explicitly, if you do not want to have it. Otherwise, FWbuilder will create general acceptance rules for all 3 basic chains ahead of all other rules:
# ================ Table 'filter', automatic rules
# accept established sessions
$IPTABLES -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
Note, that these rules would cover ALL bridges and ALL related interfaces/ports on a virtualization host (global context of acceptance)! This makes such leading rules potentially dangerous on hosts with bridges! Both during ARP spoofing attacks, but also in port flooding situations – as the ports work in a promiscuous mode. Be aware of the fact that the attack pattern discussed above could in principle be extended to guests on other bridges on the host, if the attacker knew the relevant IP addresses.
On the other side acceptance rules for established connections actually can really be convenient. My conclusion is: Either you use a set of very general iptables rules that require no connection tracking on the bridge at all – and then your guest systems must establish their own firewalls. Or :
Whatever your FW-Tool generates: Edit the resulting script and move the acceptance rule for established connections after/below the set of critical “DENY” rules on the bridge interfaces discussed above. Check in addition that the DENY rules themselves really are set as stateless rules.
Testing
Let us say kali3 pings kali5 after ARP poisoning. What can the MiM on “kali4” really see then – if no firewall rules are implemented on the host? As expected all and everything:
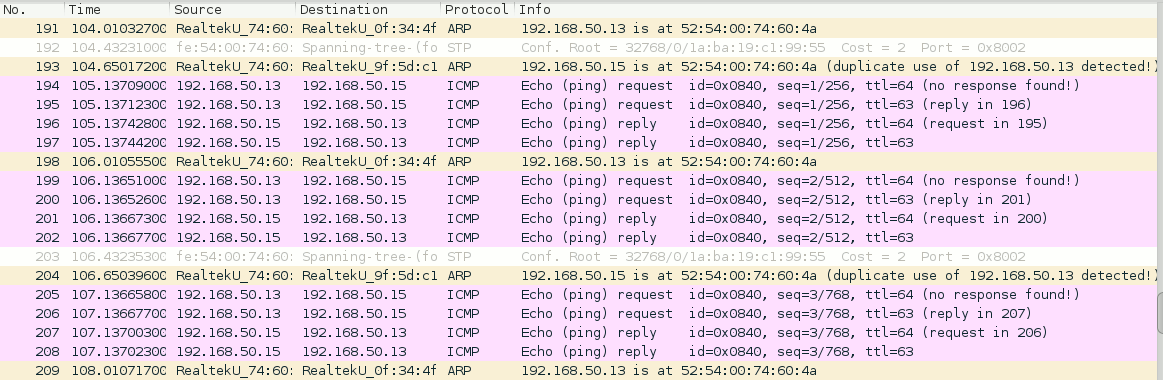
You see the poisoning packets and the redirected (duplicated) messages between kali3 and kali5. The same would of course be true for any kind of real TCP/IP communication. So without any measures the MiM can follow all communication after spoofing.
Now let us implement the iptables rules discussed above. In our test case we expect our “rule 3” to block the redirected (misguided) traffic to kali4. And really:
And at the same time on the host:
mytux:~/bin # tail -f /var/log/firewall
...
...
2016-02-23T14:41:17.783163+01:00 mytux kernel: [33572.296587] RULE 3 -- DENY IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vk64 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=837 DF PROTO=ICMP TYPE=8 CODE=0 ID=2401 SEQ=1
2016-02-23T14:41:18.790152+01:00 mytux kernel: [33573.304717] RULE 3 -- DENY IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vk64 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=869 DF PROTO=ICMP TYPE=8 CODE=0 ID=2401 SEQ=2
2016-02-23T14:41:19.798127+01:00 mytux kernel: [33574.313685] RULE 3 -- DENY IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vk64 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=977 DF PROTO=ICMP TYPE=8 CODE=0 ID=2401 SEQ=3
Good! Defense is obviously possible – even on the IP-level – as soon as we relate bridge ports to IP information!
Stopping ARP spoofing – with potential port flooding on the bridge as an aftermath
At some point in time the MiM attacker may stop his spoofing by
root@kali4:~# killall arpspoof
root@kali4:~# echo 1 > /proc/sys/net/ipv4/ip_forward
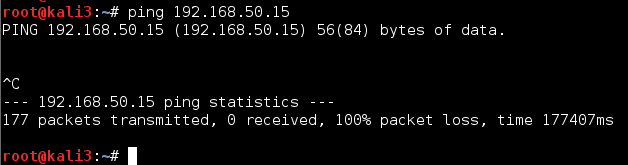
Before the poisoning jobs terminate themselves they send some packets which try to correct the corrupted ARP information on the attacked guests. However, depending on the load of the guests and the host this correction may go wrong – on one or both poisoned guests – and the old spoofed information may remain in the guests’ ARP tables:
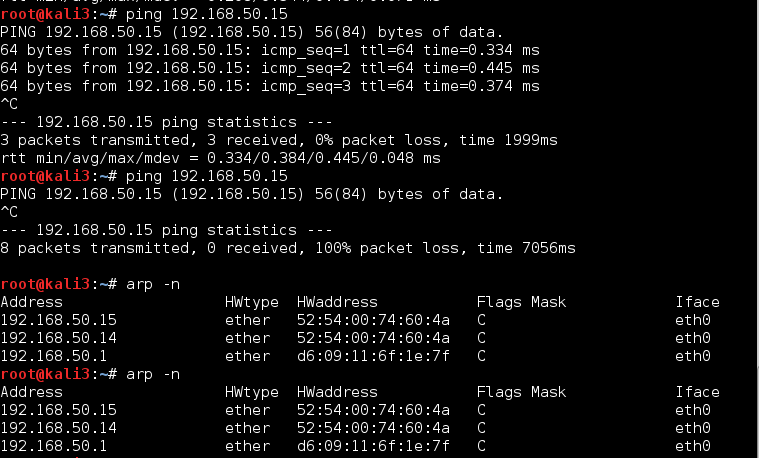
And even some seconds later:
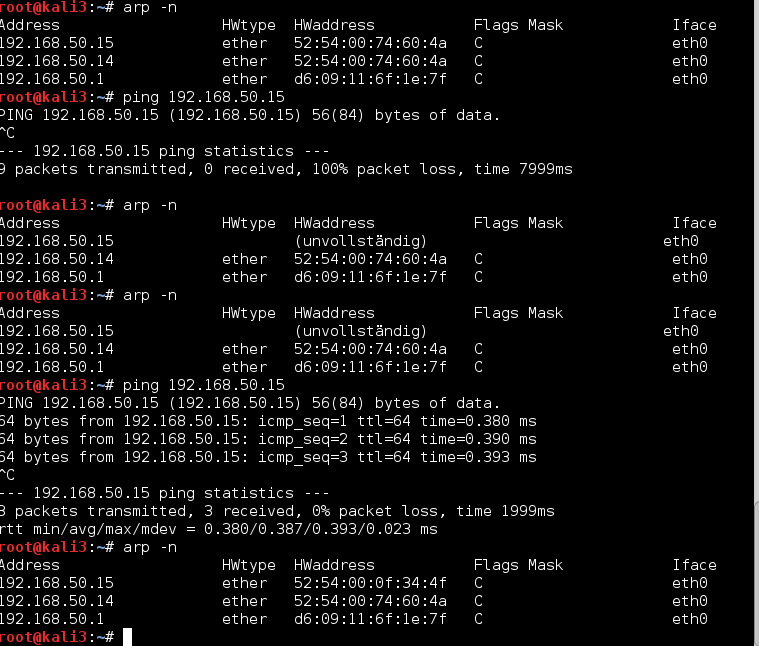
kali3 still thinks that 192.168.50.15 is located at the MAC address of kali4! How long this wrong information is kept depends on the relevant timeout parameter for local ARP table cache entries – see the output of:
$ cd /proc/sys/net/ipv4/neigh/
$ cat default/gc_stale_time
For our Debian guests this parameter typically has a value of 60 secs.
The picture above shows that on kali3 first 9 ICMP request packets were sent which got no answer. Later on a second series of pinging requests work normally again. In this specific test case – with a remaining wrong ARP information on kali3 – actually 2 interesting things happened in parallel:
mytux:~/bin # tail -f /var/log/firewall
2016-02-23T16:18:32.972806+01:00 mytux kernel: [ 1909.777744] RULE 21 -- ACCEPT IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vk65 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=19648 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=1
2016-02-23T16:18:32.972820+01:00 mytux kernel: [ 1909.777774] RULE 3 -- DENY IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vk64 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=19648 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=1
2016-02-23T16:18:32.972822+01:00 mytux kernel: [ 1909.777785] RULE 21 -- ACCEPT IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vethb2 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=19648 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=1
2016-02-23T16:18:32.972823+01:00 mytux kernel: [ 1909.777806] RULE 5 -- DENY IN=virbr4 OUT=virbr4 PHYSIN=vethb1 PHYSOUT=vnet0 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=19648 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=1
2016-02-23T16:18:32.972824+01:00 mytux kernel: [ 1909.777818] RULE 35 -- DENY IN=virbr4 OUT=virbr4 PHYSIN=vethb1 PHYSOUT=vmw1 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=19648 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=1
2016-02-23T16:18:32.972825+01:00 mytux kernel: [ 1909.777827] RULE 35 -- DENY IN=virbr4 OUT=virbr4 PHYSIN=vethb1 PHYSOUT=vmh1 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=19648 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=1
....
.....
2016-02-23T16:18:40.972821+01:00 mytux kernel: [ 1917.786358] RULE 21 -- ACCEPT IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vk65 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=20666 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=9
2016-02-23T16:18:40.972847+01:00 mytux kernel: [ 1917.786378] RULE 3 -- DENY IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vk64 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=20666 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=9
2016-02-23T16:18:40.972850+01:00 mytux kernel: [ 1917.786385] RULE 21 -- ACCEPT IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vethb2 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=20666 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=9
2016-02-23T16:18:40.972852+01:00 mytux kernel: [ 1917.786397] RULE 5 -- DENY IN=virbr4 OUT=virbr4 PHYSIN=vethb1 PHYSOUT=vnet0 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=20666 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=9
2016-02-23T16:18:40.972854+01:00 mytux kernel: [ 1917.786404] RULE 35 -- DENY IN=virbr4 OUT=virbr4 PHYSIN=vethb1 PHYSOUT=vmw1 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=20666 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=9
2016-02-23T16:18:40.972856+01:00 mytux kernel: [ 1917.786410] RULE 35 -- DENY IN=virbr4 OUT=virbr4 PHYSIN=vethb1 PHYSOUT=vmh1 MAC=52:54:00:74:60:4a:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=20666 DF PROTO=ICMP TYPE=8 CODE=0 ID=1373 SEQ=9
.....
2016-02-23T16:19:07.924844+01:00 mytux kernel: [ 1944.768264] RULE 21 -- ACCEPT IN=virbr6 OUT=virbr6 PHYSIN=vk63 PHYSOUT=vk65 MAC=52:54:00:0f:34:4f:52:54:00:9f:5d:c1:08:00 SRC=192.168.50.13 DST=192.168.50.15 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=25179 DF PROTO=ICMP TYPE=8 CODE=0 ID=1376 SEQ=1
Where do the reactions at other ports than vk64 come from? The first part of the explanation is that the bridge temporarily flooded all its ports (vk64, vk65, vethb1) with the ping requests of kali3! This in turn lead to local denial reactions on virbr6 and also on our second bridge (vribr4). For the reason of the flooding see below.
The second strange thing is that during each of the nine ping trials a successful packet submission occurs through port vk65 – but there is no log entry for an answer packet. Why is this?
Port flooding means copying of packets for the submission over all bridge ports other than the port of the incoming packet. The, in our case, wrong destination MAC addresses of the packets included. The bridge “hopes” for an answer of the addressed MAC at one of the ports. But is this going to happen in our test situation – in which kali3 sends requests out still to the wrong MAC of kali 4?
No – because despite flooding and acceptance for transport over port vk65, kali5 rightfully ignores the copied packets due to their wrong destination MAC. On the other side kali4 will not receive anything due to the iptables rules and cannot react either. So, we end up in a situation where ICMP request packets are sent by kali3 – but no answer will return from any bridge port. This in turn leads to the fact that the bridge is not learning what it needs to learn to stop the flooding. This situation will at least remain until the ARP cache table on kali3 is corrected/updated.
So only with a subsequent new ping series – and after the ARP table of kali3 has been updated – everything will work again as expected.
Addendum, 24.02.2016:
Some reader asked me via mail to explain why flooding occurred at all. This is a good question – and I have therefore added relevant remarks into the text above. Due to our limited “setageing” parameter some “guest MAC – port” relation may be deleted from the bridges forward database (FDB) after some time. (In addition we may have impacts of the STP protocol.) With our setaging parameter and the active iptables rules kali5 will drop out of the FDB pretty soon (after 30 secs): the original pinging during the attack situation will not reach kali5, and kali5 otherwise remains passive. However, also kali4 drops out 30 secs after stopping the spoofing attack from the FDB. So, we may reach a situation where kali3 still has the wrong ARP information, but kali4’s MAC is no longer in the FDB. We ended up in a kind of race condition between timeouts of the bridge’s FDB and ARP table cache renewal on the guests.
Due to the fact that either of the spoofed guests may still have wrong ARP information after the spoofing was stopped by the attacker various strange situations may occur. kali3 may have the right ARP information, but kali5 not yet. Then answering packets may be created which try to reach kali4 instead of kali3. Such packets must not be allowed by any acceptance rules (including established relation rules) – hence again: we need the DENY rules first.
What have we learned from all this?
- The stop of the ARP spoofing can leave the bridge and some of the guests in a unconsolidated mode for some time – despite a few final packets from the attacker system to restore ARP information on the attacked systems. One or two of the attacked guests and the host may still keep wrong entries in its/their ARP table(s). The duration of such a situation depends on the local timeout parameter for the ARP caching table entries on the guest systems.
- With a limited “setageing” parameter of the bridge, port flooding is not improbable during a period after the end of a ARP spoofing attack. As a consequence, the firewall rules must prevent the consequences of port flooding, too. Therefore, we need to take care not only of guest ports, but also of border ports which lead to segregated parts of the net or to other bridges.
- In the course of port flooding, response packets may be directed to wrong recipients. This status will remain until the ARP tables of the guests are updated. During such phase the defined DENY rules must be probed first before any kind of acceptance rules.
- Regarding the competition of the different timeouts on ARP caching tables and bridge FDBs: A conclusion in case of relatively stable guest-port relations might be to set the FDB timeout (setaging parameter of the bridge) to reasonably large values (in the range of a few minutes) to avoid flooding situations. On the other side the timeout for local ARP caching could be reduced as long as this does not create unreasonable ARP traffic.
What about TCP/IP packets?
If we think a bit about the general rules discussed above, we may understand that they would work also for standard TCP/IP packets of general TCP protocols. Actually, we have defined the leading denial rules for wrong “IP/port/direction”-associations without any reference to a specific protocol. So, our rules should hold in the general case, too. The reader may test this by configuring one of the guests as a web server or by using “netcat” to set up a simple server on one of the bridge guests.
We shall investigate a related full TCP scenario in one of the next posts – where we shall follow packets across 2 bridges and to the host. So, be patient, if you do not want to perform experiments, yourself.
Summary
Obviously netfilter iptables rules can not prevent ARP spoofing and resulting “man in the middle attack” trials on virtual guest systems attached to Linux bridges of a virtualization host. However, properly designed iptables rules can intercept and interrupt the redirected traffic which a MiM system attached to the bridge wants to provoke.
Appropriate iptables rules testing predefined IP-port relations on bridges may therefore supplement and accompany additional measures on the ebtables/arptables level of netfilter. However, such rules should not be undermined by leading acceptance rules related to connection tracking.
Even an already stopped ARP spoofing attack may leave the bridge and its guests in an unconsolidated status for a while. In addition flooding of packets to all bridge ports may occur. Appropriate denial rules for guest ports and Ethernet border ports in STP situations must block the resulting improper traffic. The reduction of flooding situations may require an adaption of the “setageing” parameter to reasonably large values for predictably stable configurations of guests on a bridge.
Most important: General acceptance rules for established connections should only be applied in the sequence of firewall rules AFTER all critical (denial) rules regarding unacceptable traffic across certain ports have been tested for incoming/outgoing packets. This may require explicit changes of the scripts created by Firewall tools like FWbuilder.
A significant problem is the requirement that the association of IP addresses and ports must be known or determined at the time of the definition and/or application of the filter rules. This requires persistent port naming techniques and under certain circumstances also persistent MAC distribution techniques plus DHCP restrictions for the guests within the used virtualization environment.
In the next post of this series
Linux bridges – can iptables be used against MiM attacks based on ARP spoofing ? – II
we discuss how we can extend our rules to scenarios with multiple bridges on one host – and discover that we need a special treatment of packets crossing bridge borders.