The Spice console allows users to access the graphical desktop of a Qemu based virtual machines [VM]. The performance with both data encryption and data compression is excellent, audio is no problem and the required data transfer rates to client-applications as “remote-viewer” are within reasonable limits for a (switched) LAN. In virtualization scenarios where you can organize tasks according to a scheme “one user per VM” Spice is actually an attractive tool – and even professional virtualization environments a “Proxmoxx” and “oVirt” make use of it.
In this series we look at basic setups in self-administered Intranet environments. So far we had some ups and downs regarding the tool remote-viewer. If you want to use it in a desktop virtualization environment it is an almost perfect tool. We also found it to be a very convenient and efficient remote client-tool in an Intranet when we combined it with SSH and internal data compression of the Spice protocol. See:
KVM/Qemu VMs with a multi-screen Spice console – V – remote access via remote-viewer, a network port and a SSH-tunnel
KVM/Qemu VMs with a multi-screen Spice console – IV – remote access via SSH, remote-viewer and a Unix socket
KVM/Qemu VMs with a multi-screen Spice console – III – local access with remote-viewer via a Unix socket
SSH gave us all options we needed to take care of various security issues in remote access scenarios. The KVM/Qemu server could control the interaction of remote-users with VMs by applying user-specific SSH restrictions to port-forwarding. We could establish rules to bind the Spice access to a specific VM to a specific user.
Regarding the last point the combination of remote-viewer, TLS and SASL came as a solid disappointment. TLS worked perfectly. But we had problems with SASL; see:
KVM/Qemu VMs with a multi-screen Spice console – VII – remote-viewer, qemu and SASL authentication
KVM/Qemu VMs with a multi-screen Spice console – VI – remote access with remote-viewer and TLS encryption
We got SASL authentication working in two different ways. The frustrating result of our efforts, however, was that we could not confine the access to the Spice-console of a specific VM to exactly one user.
In the end we found that it might even be better to use TLS and a VM-specific Spice password set in the VM’s XML-domain file. The problem then still is that users could share the password for a specific VM. So, we still could not ensure a scenario “one VM – one UID, only”.
In this article we, therefore, look at measures on remote client-systems to allow a TLS connection to a specific VM on the KVM/Qemu host for exactly one user. We use two different Linux tools – namely iptables and sudo – to achieve this. The recipes given below are interesting in themselves and can be applied to other scenarios where the admin wants to restrict outgoing TCP-connection on a user specific level.
Why do we care about user-specific control for Spice at all?
Assume a situation
in a small Linux oriented office where you run a bunch of VMs for special purposes on a central KVM-server.
You provide e.g. a VM (VM1) with Windows 10 ( 🙁 ) for book-keeping with a program your tax advisor understands. A user “Charlie” with a defined UID should use the VM’s Spice console, but basically only he (and his boss in the evening hours).
You have a second VM (VM2) with a Web-server for development and test purposes. Only user “Maggie” shall have access to the Spice console of VM2 on Mondays and Tuesdays and a user “Anne” on Wednesdays and Thursdays and no one else.
And then there is yet another VM (VM3) which only user “Ralph” shall access via Spice to create documents of a confidential analysis for a governmental organization.
There are multiple Linux client PCs available in the office; any of the user can use and login to any free Linux workstations. None of the user has root rights on the clients and the server.
We have thus defined a scenario of the type
One VM + Spice console < = > one user or a group of selected users.
Can you cover such a situation with remote-viewer, TLS and server-based SASL, only?
The answer of my last article was: NO. At least not by simple means. (By the way: It is not the fault of SASL. Remote-viewer, simply and unfortunately, does not provide any system-based data for the realm or for the remote-system which SASL could evaluate. The user has too much freedom …)
Do we need measures on the client-systems?
It is interesting that even Opensuse’s “Virtualization Guide” writes about some required measures on the client (restricting access to specific client-certificates for selected users) when discussing the security for libvirt and vnc as tools to access the graphical desktop of a VM. We have not come to libvirt-based tools in this series, yet, but this is already some indication that restrictions of desktop access to KVM/Qemu based VMs may sometimes require measures on the client. So, let us turn to the client-systems … Of course, we assume that such clients have a Linux OS, in my case a Opensuse Leap 15.2.
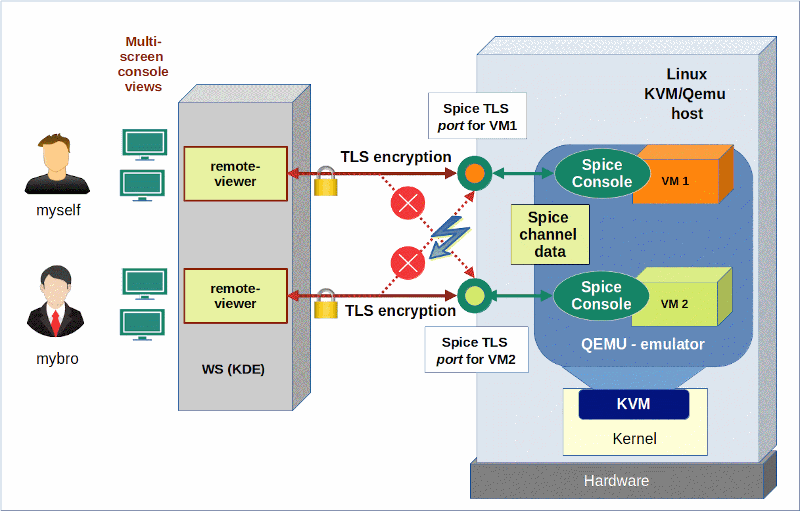
Schematic drawing
The following schematic drawing reflects the situation we want to control:
We want to make it impossible user “mybro” to access the Spice console of a VM1. Only “myself” should be able to use VM1’s Spice console via a TLS connection. The other way round: Only user “mybro” shall be allowed to connect to the the Spice console of VM2 with remote-viewer. Cross-connections are forbidden; each user gets access to one defined VM only.
We use the same systems as in the last articles: A KVM/Qemu server host “MySRV” (IP: 192.168.2.2) with a Leap 15.2 OS on it, a test-VM1 “debianx” with a Kali-OS on it and a client-system “MyLAP” (a laptop with a Leap 15.2 OS; IP: 192.168.2.22). On MyLap we have a user “myself” and a user “mybro”. VM1 (“debianx”) gets the (TLS-) port 20002 on the server, and VM2 (“leaptest”) the (TLS-) port 20004.
We shall perform the experiments in this article with a Qemu set up without SASL, but each VM configured for an individual password. (As we already know it will only means a small difference in the form of the authentication dialog. We will not be asked for a username.) The scenario can easily be changed to SASL authentication.
Strategies to allow Spice access to a VM’s desktop only for a specific user
There are three major strategies we can follow:
Strategy 1: We could think about a specific TLS client certificate for a connection to a VM and to make it accessible only to the user in question. Such a
strategy would require that client certificates are supported by Qemu and Spice.
Strategy 2: We could use iptables and add user-specific rules for outgoing data to certain TLS-ports on the server. As user-related rules can only be set for the “output chain” we cannot set any such user-specific filters for our problem on the server.
Strategy 3: We take the choice of the target port on the server away from the user as well as any free access to the remote-viewer command namely by changing file permissions, setting up special sudo rules and/or enforcing him/her to run a shell script which starts remote-viewer with a pre-defined target port for him/her.
The strategies (if working) can be combined. Even if the firewall of strategy 2 failed the user would only get access to a specific VM by restrictions of strategy 3. But all these things are a bit complicated and they all depend on the user not being able to get root rights, the firewall being set up at every system-startup and the sudo rules being tight. This is crucial; our KVM/Qemu server with TLS and SASL could only block connections from certain IPs, but not really users.
We could extend strategy 3 to a network namespace – but it won’t help too much as we then would again need to apply routing and related firewall rules. Or to sudo rules. We could also think about using different networks for different VMs and thus a port-IP-VM-relation – but we would still depend on user-specific firewall rules on the clients.
Strategy 1: What about Spice and TLS client certificates?
Here I come with bad news:
If you activate the option “default_tls_x509_verify = 1” in “/etc/livirt/qemu.conf” it is simply ignored. One can guess it from a lack of required parameters in the qemu-command created by virt-manager. Even if and when you provide client certificates in the required directories on the server and the client. In contrast to VNC-settings there is no option like “spice_tls_x509_verify = 1” available. If you set it by yourself, it is silently ignored.
So, client-certificates will be of no help with Spice and remote-viewer. The situation my be different for the libvirt-dependent “virt-viewer” tool. But this is the topic of a future blog post.
Strategy 2: netfilter/iptables to the rescue
I assume that you have some tool in place on your Linux systems to configure your own iptables-rules. Professionals may write their own scripts. Independent of your interface to netfilter/iptables, it is obvious that working with firewall rules in a productive environment is a risky business. Therefore:
Disclaimer: I take no responsibility whatever for the consequences of the approach describes below and its application to your computers. The iptables-rules have to be tested carefully before making them productive and their setup on Linux hosts must be supervised by an expert.
In my network environments I still cling to the tool “fwbuilder” because it gives you a good graphical overview for most purposes and it allows for more complex configurations than e.g. frontends to firewalld or ufw. So, let me show you how to set up a basic set of user-specific iptables rules with fwbuilder and then have a closer look at the contents of the created statements of the firewall script.
fwbuilder allows you to set up “users” with a defined UID in the object catalog for “services”:
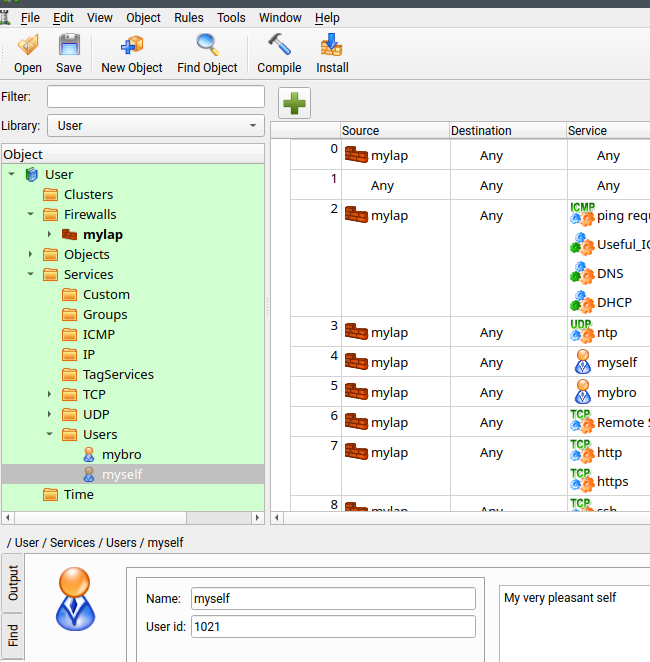
This may seem strange; but the meaning is the following:
- Using a “user” as a “service” will trigger the creation of a rule for the OUTPUT chain which matches the user of outgoing connection
packets against an owner with a defined UID and then triggers a reaction. - To cover the reaction in fwbuilder we “branch off” into a specific rule-set for the user. On the iptables level this corresponds to a user-defined rule-chain as a reaction target.
- The filter-rules for data packets in the user-defined chain themselves then lead to certain final reactions in the sense of “allow” or “deny”.
In pseudo-code: IF a user matches an UID THEN apply a set of filter rules with their own final reactions.
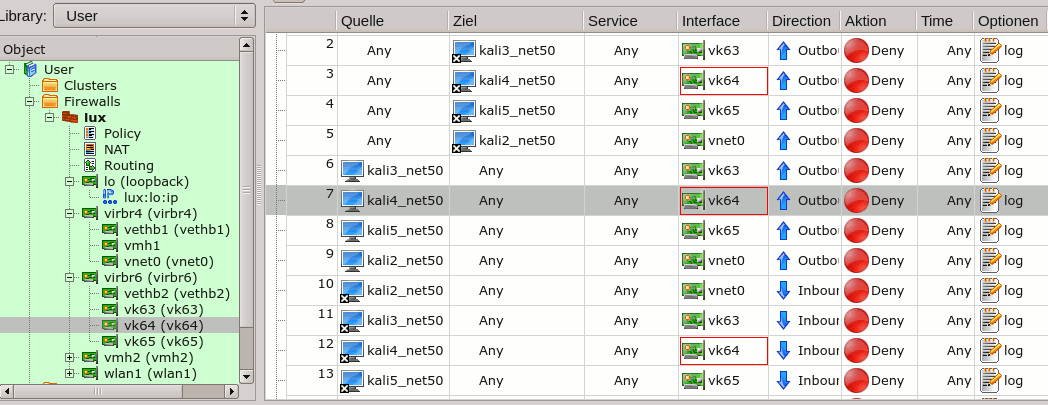
In Fwbuilder a set of filter-rules is usually put into an object called “policy”. The following image shows some rules of the main “policy” on “MyLap”:
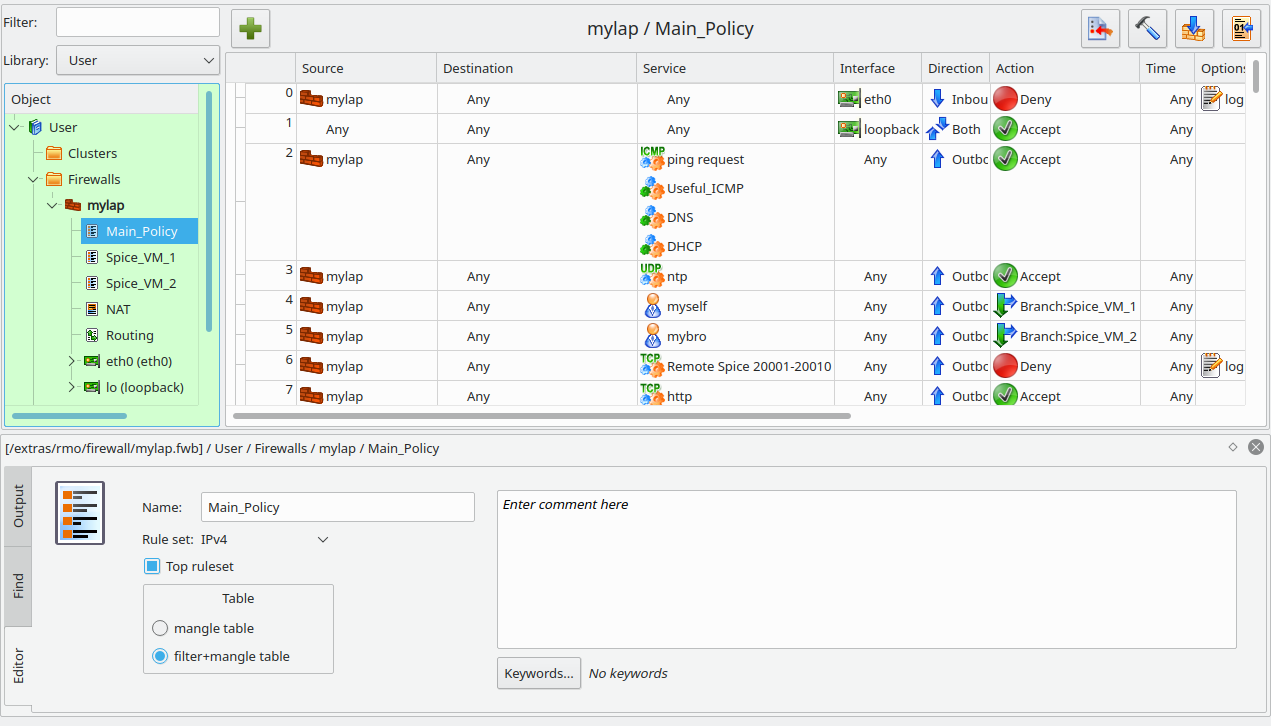
You see that rules 4 and 5 include users “myself” and “mybro”; the rules branch off to policies “Spice_VM_1” and “Spice_VM_2”, respectively.
Rule 6 blocks a whole bunch of TCP-ports used for VMs on the KVM/Qemu server for any other user than “myself” and “mybro”.
Policy “Spice_VM_1” contains one rule, only:
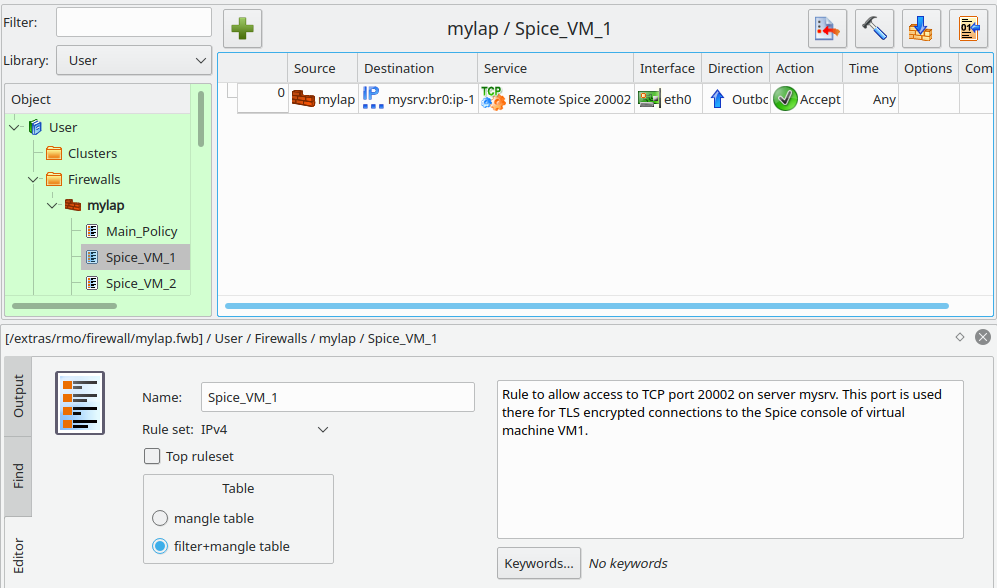
This rule specifies a certain interface and the IP of the target host “mysrv”. We allow access to port 20002 – corresponding to the TLS port defined for our test VM “debianx” (VM1). Something analogous holds for our second user “mybro”. He gets access to another virtual machine “VM2” which we have bound to port 20004 on the KVM-server for external TLS connections.

Now, let us look at the iptables statements generated by fwbuilder:
# ================ Table 'filter', automatic rules
# accept established sessions
$IPTABLES -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
# backup ssh access from a admin host
$IPTABLES -A INPUT -p tcp -m tcp -s 192.168.44.12/255.255.255.255 --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
$IPTABLES -A OUTPUT -p tcp -m tcp -d 192.168.44.12/255.255.255.255 --sport 22 -m state --state ESTABLISHED,RELATED -j ACCEPT
# ================ Table 'filter', rule set Spice_VM_1
#
# Rule Spice_VM_1 0 (eth0)
#
echo "Rule Spice_VM_1 0 (eth0)"
#
$IPTABLES -N Spice_VM_1
$IPTABLES -N Cid40091X30615.0
$IPTABLES -A Spice_VM_1 -o eth0 -p tcp -m tcp -d 192.168.2.2 --dport 20002 -m state --state NEW -j Cid40091X30615.0
$IPTABLES -A Cid40091X30615.0 -s 192.168.2.22 -j ACCEPT
$IPTABLES -A Cid40091X30615.0 -s 192.168.2.22 -j ACCEPT
# ================ Table 'filter', rule set Spice_VM_2
#
# Rule Spice_VM_2 0 (eth0)
#
echo "Rule Spice_VM_2 0 (eth0)"
#
$IPTABLES -N Spice_VM_2
$IPTABLES -N Cid40661X30615.0
$IPTABLES -A Spice_VM_2 -o eth0 -p tcp -m tcp -d 192.168.2.2 --dport 20004 -m state --state NEW -j Cid40661X30615.0
$IPTABLES -A Cid40661X30615.0 -s 192.168.2.22 -j ACCEPT
$IPTABLES -A Cid40661X30615.0 -s 192.168.2.22
-j ACCEPT
# ================ Table 'filter', rule set Main_Policy
#
# Rule Main_Policy 0 (eth0)
#
echo "Rule Main_Policy 0 (eth0)"
#
# Antispoofing
$IPTABLES -N In_Main_Policy_0
$IPTABLES -A INPUT -i eth0 -s 192.168.2.22 -j In_Main_Policy_0
$IPTABLES -A INPUT -i eth0 -s 192.168.4.22 -j In_Main_Policy_0
$IPTABLES -A FORWARD -i eth0 -s 192.168.2.22 -j In_Main_Policy_0
$IPTABLES -A FORWARD -i eth0 -s 192.168.4.22 -j In_Main_Policy_0
$IPTABLES -A In_Main_Policy_0 -j LOG --log-level info --log-prefix "RULE 0 -- DENY "
$IPTABLES -A In_Main_Policy_0 -j DROP
#
# Rule Main_Policy 1 (lo)
#
echo "Rule Main_Policy 1 (lo)"
#
$IPTABLES -A INPUT -i lo -m state --state NEW -j ACCEPT
$IPTABLES -A OUTPUT -o lo -m state --state NEW -j ACCEPT
#
# Rule Main_Policy 2 (global)
#
echo "Rule Main_Policy 2 (global)"
#
# ICMP, DNS, DHCP
$IPTABLES -A OUTPUT -p icmp -m icmp --icmp-type 3 -m state --state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p icmp -m icmp --icmp-type 0/0 -m state --state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p icmp -m icmp --icmp-type 8/0 -m state --state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p icmp -m icmp --icmp-type 11/0 -m state --state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p icmp -m icmp --icmp-type 11/1 -m state --state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p tcp -m tcp --dport 53 -m state --state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p udp -m udp -m multiport --dports 68,67,53 -m state --state NEW -j ACCEPT
#
# Rule Main_Policy 3 (global)
#
echo "Rule Main_Policy 3 (global)"
#
$IPTABLES -A OUTPUT -p udp -m udp --dport 123 -m state --state NEW -j ACCEPT
#
# Rule Main_Policy 4 (global)
#
echo "Rule Main_Policy 4 (global)"
#
$IPTABLES -A OUTPUT -m owner --uid-owner 1021 -j Spice_VM_1
#
# Rule Main_Policy 5 (global)
#
echo "Rule Main_Policy 5 (global)"
#
$IPTABLES -A OUTPUT -m owner --uid-owner 1022 -j Spice_VM_2
#
# Rule Main_Policy 6 (global)
#
echo "Rule Main_Policy 6 (global)"
#
$IPTABLES -N Out_Main_Policy_6
$IPTABLES -A OUTPUT -p tcp -m tcp --dport 20001:20010 -j Out_Main_Policy_6
$IPTABLES -A Out_Main_Policy_6 -j LOG --log-level info --log-prefix "RULE 6 -- DENY "
$IPTABLES -A Out_Main_Policy_6 -j DROP
#
...
...
These are simple rules which the experienced reader will have no difficulty to interpret. (The reader also sees that I have multiple IPs on eth0, but this does not affect our present topic).
I leave the test to you. You should see that user “myself” can access VM1 (debianx) whilst user “mybro” and any other users cannot. User “mybro” instead can access VM2 on the server.
Important note:
Do not forget to write a small systemd service which starts your firewall automatically during the startup of your client-system.
I have written about his topic somewhere else in this blog already. believe me its easy.
Strategy 3: Using sudo
Working with “sudo” and manipulating the file “/etc/sudoers” is somewhat risky. Therefore:
Disclaimer: I take no responsibility whatever for the consequences of the sudo approach describe below and its application to your computers. The sudoer rules have to be tested carefully before the are used in a production environment and their setup must be supervised by an expert.
The settings below work for an Opensuse Leap system – partially due to the default settings there.
A standard problem with sudoer rules for graphical applications is the handling of the access to the X11
display if you need to start programs as another user (e.g. root). (Things may be even worse with Wayland; but I have no experience with it). To keep things simple it is a worthwhile investment to think a bit about the precise nature of your sudo-objective.
In our case we want enforce a user-specific usage of the command remote-viewer. More precisely:
- We want to disallow the usage of remote-viewer for most users. And even selected users shall not be able to call or invoke remote-viewer directly and freely.
- We want to enforce user-specific arguments to the command “remote-viewer”, if executed by certain selected users.
- If possible we do not want to run any remote-tool with root-rights at all.
- We want to keep our user-specific firewall rules in place and not to create new ones.
- X11-display access shall be possible.
The answer to this challenge is a bit tricky. It first looks like you need to write a separate script (accessible to root) which evaluates UIDs or SUD_UIDs and then calls remote-viewer with appropriate arguments.
But you will then be confronted with problems to access the X11-display of the user issuing the script. In addition rule 3 above forces you to start the required remote-viewer command in the end as a specific user via “sudo -u USER” or “su -c ‘…’ USER”. This in turn forces you to allow “USER” to execute the remote-viewer command anyway according to a specific sudo (!) rule for USER. Therefore, he/she must be able to read and execute the remote-viewer command. But then he/she could execute it outside freely without sudo – and again use any arguments he/she likes. It took me a while to find a way out.
The right approach is to find a rule working for the user in question, first, before you turn to a script as a mediator. On the other side: The user must NOT be allowed to use “remote-viewer” freely – neither by user or group access rights. This seeming contradiction is solved by the following steps on our client-system; we describe the rules below for user “myself”. You must execute most of the commands as root:
- Step 1: Create a special group, e.g. named “spicegrp”. Do NOT make user “myself” a member of this group!
- Step 2: Change the ownership and access rights of “/usr/bin/remote-viewer” according to
- chown root.spicegrp /usr/bin/remote-viewer
- chmod 750 /usr/bin/remote-viewer
- Step 3: Check that remote-viewer can no longer be executed by user “myself”.
- Step 4: Start editing the file “/etc/sudoers” with visudo.
- Step 5: Add the following lines and turn some existing lines into comments:
.... Defaults env_reset Defaults env_keep = "LANG LC_ADDRESS LC_CTYPE LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE LC_ATIME LC_ALL LANGUAGE LINGUAS XDG_SESSION_COOKIE" Defaults:myself env_keep += "DISPLAY" #Defaults targetpw # ask for the password of the target user i.e. root #ALL ALL=(ALL) ALL myself ALL=(myself:spicegrp) /usr/bin/remote-viewer -- spice\://mysrv.anraconc.de?tls-port=20002 # myself ALL=(myself:spicegrp) NOPASSWD: /usr/bin/remote-viewer -- spice\://mysrv.anraconc.de?tls-port=20002 # mybro ALL=(mybro:spicegrp) NOPASSWD: /usr/bin/remote-viewer -- spice\://mysrv.anraconc.de?tls-port=20004
This is all we basically need for the user myself. An extension to
user “mybro” should be clear. See the commented line for mybro.
The sudoer statements – also the commented ones – deserve some short explanation:
We reset the environment, but we keep some language settings for sudoer users. More important: We keep the “DISPLAY” variable of the environment of sudoer user “myself”. Meaning, it will be available when commands are executed with his/her UID. Hereby, we avoid major X11 trouble. The two commented lines in the middle correspond to the the objective that sudoer users should provide their own passwords instead of the root password to execute the commands in the prescribed form.
And then comes some sudo vodoo:
We only define a rule for the user “myself”: We allow him/her to execute the command remote-viewer with his own UID, but with a different group. This gives him access to “/usr/bin/remote-viewer” under “sudo” conditions ( only !). But, in no way else on a shell’s command line, as he/her no longer has access rights to “/usr/bin/remote-viewer” and is no member of “spicegrp”!
The other part of the magic is that the sudoer-mechanism checks the precise form by which the user in question (here: myself) executes the command. It compares the command exactly to the form given in the rule line including the command’s arguments!
myself ALL=(myself:spicegrp) /usr/bin/remote-viewer -- spice\://mysrv.anraconc.de?tls-port=20002
The command and the arguments to it are together handled as one string for comparison!
Thus we have a user “myself” who can only use remote-viewer with “sudo” and he/she is forced to provide a specific argument. And when he issues the command the firewall rules defined in the first part of this post should open doors to the VM as the execution is done with his/her UID!
What will the required sudo command for a successful access to the VM1 (debianx) at TLS-port 20002 on server MySRV look like:
sudo -u myself -g spicegrp remote-viewer — spice://mysrv.anraconc.de?tls-port=20002
You took notice of the argument for the group?
Test for a sudoer user
Let us test our theory (sorry for the German system messages, tried to translate them):
myself@mylap:~> remote-viewer -- spice://mysrv.anraconc.de?tls-port=20002 -bash: /usr/bin/remote-viewer: Keine Berechtigung myself@mylap:~> # Keine Berechtigung = No access right myself@mylap:~> # Now with sudo - but wrong port 20004 myself@mylap:~> sudo -u myself -g spicegrp remote-viewer -- spice://mysrv.anraconc.de?tls-port=20004 [sudo] Passwort für myself: Leider darf der Benutzer myself »/usr/bin/remote-viewer -- spice://mysrv.anraconc.de?tls-port=20004« als myself:spicegrp auf mylap.anraconc.de nicht ausführen. myself@mylap:~> # Translation: Sorry, but user myself is not allowed to execute »/usr/bin/remote-viewer -- spice://beta.rux.anraconb.de?tls-port=20004« as myself:spicegrp on mylap.anraconc.de. myself@mylap:~> # Now with sudo - but the right port 20002 myself@mylap:~> sudo -u myself -g spicegrp remote-viewer -- spice://mysrv.anraconc.de?tls-port=20002
And now we get the familiar dialog to authenticate :
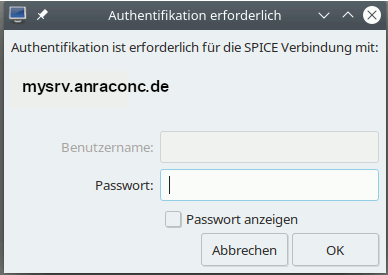
Our firewall obviously has let us through. And – after filling in the VM-specific password (we work without SASL here; see above), we get:
Good!
I leave
it to the reader extend the whole thing to two users and to test all combinations out.
Making things a bit easier for the users
An authorized user has to type a lot of things to make the sudo command work. One thing, you can think about, is to not require a password for the sudo command. (Personally, I would not do this; a password is a last security barrier in case of configuration mistakes. But, in principle it is possible to work without a password in this specific case – after you have checked out and tested all security implications). The entry in the “/etc/sudoers” file then would look like
.... myself ALL=(myself:spicegrp) NOPASSWD: /usr/bin/remote-viewer -- spice\://mysrv.anraconc.de?tls-port=20002 ...
Another reduction of typing work comes through a script which readers can read and execute, but not change. The script could make all the relevant decisions for a user. A very simplified version would in my test scenario contain statements like:
#!/bin/bash
host="myserv.anraconc.de"
myself_port="20002"
mybro_port="20004"
Myself_UID="1021"
Mybro_UID="1022"
if test $SUDO_UID
then
if test $UID -ne $SUDO_UID
then
echo "error - you are not allowed to run this command as another user"
exit
fi
fi
if test $UID -eq $Myself_UID
then
echo "Hello Ralph"
msg="You are entering the Spice console of VM \"debianx\" - happy working"
echo $msg
sudo -u "#$UID" -g spicegrp /usr/bin/remote-viewer -- spice://$host?tls-port=$myself_port
elif test $UID -eq $Mybro_UID
then
echo "Hello Brother"
msg4="You are entering the Spice console of VM \"leaptest\" - happy working"
echo $msg4
sudo -u "#$UID" -g spicegrp /usr/bin/remote-viewer -- spice://$host?tls-port=$mybro_port
else
echo "Sorry, you are not allowed to access VMs"
fi
Note that the script would ask for a password before executing the sudo statement enclosed – if you had defined a password request in the sudoer file.
If you absolutely wanted to obfuscate the information contained in this script you could again use the trick with sudo and the special group spicegrp. You would the add lines
myself ALL=(myself:spicegrp) /usr/bin/rviewer myself ALL=(mybro:spicegrp) /usr/bin/rviewer
to the “/etc/sudoers”-file
Important note:
You must not forget to check the fie permission of the file “/usr/bin/remote-viewer” after SW-updates or upgrades of your system.
I would recommend to start a small scheduled job or a service to check the rights settings frequently.
Conclusion
Remote-viewer connections to VMs cannot be controlled on a user level by the KVM/Qemu server if we just used TLS and SASL. We can set up a VM specific password. But external connections to a VM specific TLS port can only be blocked for external systems and IPs on the server.
However, on Linux client-systems iptables helps us to allow access to the Spice console of a specific VM for a selected user, only. This can be achieved by setting up user specific iptables rules on client-systems. This post has shown you how to create such rules for the OUTPUT chain with fwbuilder. We must set up a systemd service to implement these rules automatically at system (and network) startup.
To restrict users on Linux client systems even more we applied the sudo mechanism in a very specific way: we enforced the usage of certain arguments to the remote-viewer command for specific users. I think the method I discussed is safe; if you find a caveat please send me a mail.
Both strategies can and should be applied in Intranets where we want to provide remote-viewer and the Spice consoles of Qemu VMs as real working instruments.