I have to work with Eclipse (version 4.32) again for a while. After two days of relatively intensive work, I am a bit frustrated. One reason is the small size of the icons – 16×16 px. Not only in the main icon taskbar. There are minuscule symbols elsewhere – e.g. in the bar on the left side of the editor section. Regarding e.g. the tiny symbol for code folding: You can almost not see the “+” or “-” symbols on a high resolution screen …
One can scale almost all font-sizes within Eclipse – but not such a basic thing as the icon/symbol size or the icon bar height.
I have three QHD screens (2560×1440) at my present workplace. At another site there are 2 4K screens. The following image can give you an impression for the QHD situation – if you have a QHD, UHD or 4K screen yourself and not zoomed the browser contents already. For screens with lower resolution see below.
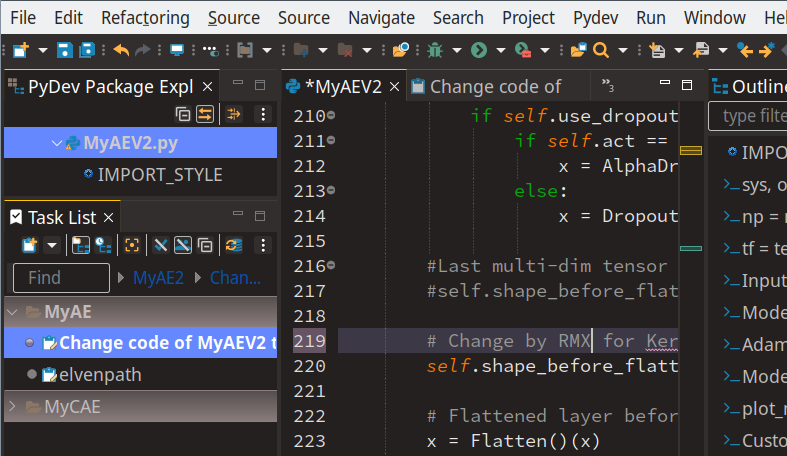
Before you say this looks quite OK, check the following:
- Open this post on a desktop screen in a window wider than 800 px.
- Enforce normal content size size in your browser (no zoom! Ctrl-0).
- Get a natural distance to your working QHD, UHD or 4K monitor (like 80+ cm). In case you have a QHD screen you get already the right impression.
- Users who just have a monitor with a 1920×1200 resolution must in addition downscale their browser contents to around 80% (QHD) or 55% (UHD, 4K) to get the right impression of the problem. (After Ctrl-0)
- Folks with QHD get the right 4K impression by scaling down to 66%. (After Ctrl-0)
While for QHD the working conditions may still appear to be OK, you get a real problem for UHD and 4K resolutions. The font-size may still be OK (after having adapted it). The unadaptable symbol sizes, however, are far too small. At least in my opinion. But even on my standard QHD screens I personally do not feel comfortable after a while.
In this post I want to share some workarounds. The methods described may be interesting for other GTK applications, too. Keep in mind that the images in this post may give you a wrong impression if you zoomed the browser contents. But later on, when I demonstrate the effect of some measures, only relative sizes of fonts and icons are of interest.
Continue reading →