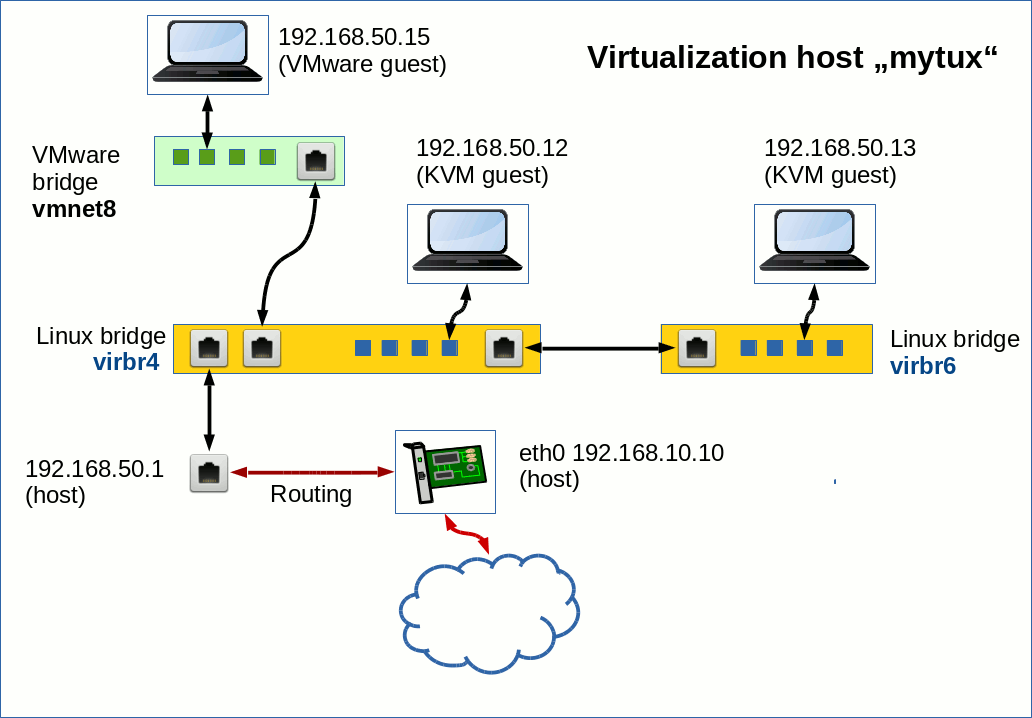
Recently, I started writing some blog posts about my first experiences with LXC-containers and libvirt/virt-manager. Whilst gathering knowledge about LXC basics I stumbled across four hurdles for dummies as me, who would like to experiment with network namespaces, veth devices and bridges on the command line and/or in the context of LXC-containers built with virt-manager:
- When you use virt-manager/libvirt to set up LXC-containers you are no longer able to use the native LXC commands to deal with these containers. virt-manager/virsh/libvirt directly use the kernel API for cgroups/namespaces and provide their own and specific user interfaces (graphical, virsh, XML configuration files) for the setup of LXC containers and their networks. Not very helpful for quick basic experiments on virtual networking in network namespaces ….
- LXC-containers created via virt-manager/virsh/libvirt use unnamed namespaces which are identified by unique inode numbers, but not by explicit names. However, almost all articles on the Internet which try to provide a basic understanding of network namespaces and veth devices explicitly use “ip” command options for named namespaces. This raises the question: How to deal with unnamed network namespaces?
- As a beginner you normally do not know how to get a shell for exploring an existing unnamed namespace. Books offer certain options of the “ip”-command – but these again refer to named network namespaces. You may need such a shell – not only for basic experiments, but also as the administrator of the container’s host: there are many situations in which you would like to enter the (network) namespace of a LXC container directly.
- When you experiment with complex network structures you may quickly loose the overview over which of the many veth interfaces on your machine is assigned to which (network) namespace.
Objectives and requirements
Unfortunately, even books as “Containerization with LXC” of K. Ivanov did not provide me with the few hints and commands that would have been helpful. I want to close this gap with some blog posts. The simple commands and experiments shown below and in a subsequent article may help others to quickly setup basic network structures for different namespaces – without being dependent on named namespaces, which will not be provided by virt-manager/libvirt. I concentrate on network namespaces here, but some of the things may work for other types of namespace, too.
After a look at some basics, we will create a shell associated with a new unnamed network namespace which will be different from the network namespace of other system processes. Afterwards we will learn how to enter an existing unnamed namespaces by a new shell. A third objective is the attachment of virtual network devices to a network namespace.
In further articles we will use our gathered knowledge to attach veth interfaces of 2 different namespaces to virtual bridges/switches in yet a third namespace, then link the host to the bridge/switch and test communications as well as routing. We shall the extend our virtual networking scenario to isolated groups of namespaces (or containers, if you like) via VLANs. As a side aspect we shall learn how to use a Linux bridge for defining VLANs.
All our experiments will lead to temporary namespaces which can quickly be cretated by scripts and destroyed by killing the basic shell processes associated with them.
Requirements: The kernel should have been compiled with option “CONFIG_NET_NS=y”. We make use of userspace tools that are provided as parts of a RPM or DEB packet named “util-linux” on most Linux distributions.
Namespaces
Some basics first. There are 6 different types of “namespaces” for the isolation of processes or process groups on a Linux system. The different namespace types separate
- PID-trees,
- the networks,
- User-UIDs,
- mounts,
- inter process communication,
- host/domain-names (uts) of process groups
against each each other. Every process on a host is attached to certain namespace (of each type), which it may or may not have in common with another process. Note that the uts-namespace type provides an option to give a certain process an uts-namespace which may get a different hostname than the original host of the process!
“Separation” means: Limitation of the view on the process’ own environment and on the environment of other processes on the system. “Separation” also means a limitation of the control a process can get on processes/environments associated with other namespaces.
Therefore, to isolate LXC containers from other containers and from the host, the container’s processes will typically be assigned to distinct namespaces of most of the 6 types. In addition: The root filesystem of a LXC containers typically resides in a chroot jail.
Three side remarks:
- cgroups limit the ressource utilization of process groups on a host. We do not look at cgroups in this article.
- Without certain measures the UID namespace of a LXC container will be the same as the namespace of the host. This is e.g. the case for a standard container created with virt-manager. Then root in the container is root on the host. When a container’s basic processes are run with root-privileges of the host we talk of a “privileged container”. Privileged containers pose a potential danger to the host if the container’s environment could be left. There are means to escape chroot jails – and under certain circumstances there are means to cross the borders of a container … and then root is root on the host.
- You should be very clear about the fact that a secure isolation of processes and containers on a host depend on other more sophisticated isolation mechanisms beyond namespaces and chroot jails. Typically, SE Linux or Apparmor rules may be required to prevent crossing the line from a namespace attached process to the host environment.
In our network namespace experiments below we normally will not separate the UID namespaces. If you need to do it, you must map a non-privileged UID (> 1000) on UID 0 inside the namespace to be able to perform certain network operations. See the options in the man pages of the commands used below for this mapping.
Network namespaces
The relevant namespace type for the network environment (NICs, bridges etc.) to which a process has access to is the “network namespace”. Below I will sometimes use the abbreviation “net-ns” or simply “netns”.
When you think about it, you will find the above statements on network isolation a bit unclear:
In the real world network packets originate from electronic devices, are transported through cables and are then distributed and redirected by other devices and eventually terminate at yet other electronic devices. So, one may ask: Can a network packet created by a (virtual) network device within a certain namespace cross the namespace border (whatever this may be) at all? Yes, they can:
Network namespaces affect network devices (also virtual ones) and also routing rules coupled to device ports. However, network packets do NOT care about network namespaces on OSI level 2.
To be more precise: Network namespace separation affects network-devices (e.g. Ethernet devices, virtual Linux bridges/switches), IPv4/IPv6 protocol stacks, routing tables, ARP tables, firewalls, /proc/net, /sys/class/net/, QoS policies, ports, port numbers, sockets. But is does not stop an Ethernet packet to reach an Ethernet device in another namespace – as long as the packet can propagate through the virtual network environment at all.
So, now you may ask what virtual means we have available to represent something like cables and Ethernet transport between namespaces? This is one of the purposes veth devices have been invented for! So, we shall study how to bridge different namespaces by the using the 2 Ethernet interfaces of veth devices and by using ports of virtual Linux bridges/switches.
However, regarding container operation you would still want the following to be true for packet filtering:
A fundamental container process, its children and network devices should be confined to devices of a certain “network namespace” because they should not be able to have any direct influence on network devices of other containers or the host.
And: Even if packets move from one network namespace to another you probably want to be able to restrict this traffic in virtual networks as you do in real networks – e.g by packet filter rules (ebtables, iptables) or by VLAN definitions governing ports on virtual bridges/switches.
Many aspects of virtual bridges, filtering, VLANs can be tested already in a simple shell based namespace environment – i.e. without full-fletched containers. See the forthcoming posts for such experiments …
Listing network namespaces on a host
The first thing we need is an overview over active namespaces on a host. For listing namespaces we can use the command “lsns” on a modern Linux system. This command has several options which you may look up in the man pages. Below I show you an excerpt of the output of “lsns” for network namespaces (option “-t net”) on a system where a LXC container was previously started by virt-manager:
mytux:~ # lsns -t net -o NS,TYPE,PATH,NPROCS,PID,PPID,COMMAND,UID,USER
NS TYPE PATH NPROCS PID PPID COMMAND UID USER
4026531963 net /proc/1/ns/net 389 1 0 /usr/lib/systemd/system 0 root
4026540989 net /proc/5284/ns/net 21 5284 5282 /sbin/init 0 root
Actually, I have omitted some more processes with separate namespaces, which are not relevant in our context. So, do not be surprised if you should find more processes with distinct network namespaces on your system.
The “NS” numbers given in the output are so called “namespace identification numbers”. Actually they are unique inode numbers. (For the reader it may be instructive to let “lsns” run for all namespaces of the host – and compare the outputs.)
Obviously, in our case there is some process with PID “5282”, which has provided a special net-ns for the process with PID “5284”:
mytux:~ # ps aux | grep 5282 root 5282 0.0 0.0 161964 8484 ? Sl 09:58 0:00 /usr/lib64/libvirt/libvirt_lxc --name lxc1 --console 23 --security=apparmor --handshake 26 --veth vnet1
This is the process which started the running LXC container from the virt-manager interface. The process with PID “5284” actually is the “init”-Process of this container – which is limited to the network namespace created for it.
Now let us filter or group namespace and process information in different ways:
Overview over all namespaces associated with a process
This is easy – just use the option “-p” :
mytux:~ # lsns -p 5284 -o NS,TYPE,PATH,NPROCS,PID,PPID,COMMAND,UID,USER
NS TYPE PATH NPROCS PID PPID COMMAND UID USER
4026531837 user /proc/1/ns/user 416 1 0 /usr/lib/systemd/systemd --switched-root --system --deserialize 24 0 root
4026540984 mnt /proc/5284/ns/mnt 20 5284 5282 /sbin/init 0 root
4026540985 uts /proc/5284/ns/uts 20 5284 5282 /sbin/init
0 root
4026540986 ipc /proc/5284/ns/ipc 20 5284 5282 /sbin/init 0 root
4026540987 pid /proc/5284/ns/pid 20 5284 5282 /sbin/init 0 root
4026540989 net /proc/5284/ns/net 21 5284 5282 /sbin/init 0 root
Looking up namespaces for a process in the proc-directory
Another approach for looking up namespaces makes use of the “/proc” directory. E.g. on a different system “mylx“, where a process with PID 4634 is associated with a LXC-container:
mylx:/proc # ls -lai /proc/1/ns total 0 344372 dr-x--x--x 2 root root 0 Oct 7 11:28 . 1165 dr-xr-xr-x 9 root root 0 Oct 7 09:34 .. 341734 lrwxrwxrwx 1 root root 0 Oct 7 11:28 ipc -> ipc:[4026531839] 341737 lrwxrwxrwx 1 root root 0 Oct 7 11:28 mnt -> mnt:[4026531840] 344373 lrwxrwxrwx 1 root root 0 Oct 7 11:28 net -> net:[4026531963] 341735 lrwxrwxrwx 1 root root 0 Oct 7 11:28 pid -> pid:[4026531836] 341736 lrwxrwxrwx 1 root root 0 Oct 7 11:28 user -> user:[4026531837] 341733 lrwxrwxrwx 1 root root 0 Oct 7 11:28 uts -> uts:[4026531838] mylx:/proc # ls -lai /proc/4634/ns total 0 38887 dr-x--x--x 2 root root 0 Oct 7 09:36 . 40573 dr-xr-xr-x 9 root root 0 Oct 7 09:36 .. 341763 lrwxrwxrwx 1 root root 0 Oct 7 11:28 ipc -> ipc:[4026540980] 341765 lrwxrwxrwx 1 root root 0 Oct 7 11:28 mnt -> mnt:[4026540978] 345062 lrwxrwxrwx 1 root root 0 Oct 7 11:28 net -> net:[4026540983] 38888 lrwxrwxrwx 1 root root 0 Oct 7 09:36 pid -> pid:[4026540981] 341764 lrwxrwxrwx 1 root root 0 Oct 7 11:28 user -> user:[4026531837] 341762 lrwxrwxrwx 1 root root 0 Oct 7 11:28 uts -> uts:[4026540979]
What does this output for 2 different processes tell us? Obviously, the host and the LXC container have different namespaces – with one remarkable exception: the “user namespace”! They are identical. Meaning: Root on the container is root on the host. A typical sign of a “privileged” LXC container and of potential security issues.
List all processes related to a given namespace?
“lsns” does not help us here. Note:
“lsns” only shows you the lowest PID associated with a certain (network) namespace.
So, you have to use the “ps” commands with appropriate filters. The following is from a system, where a LXC container is bound to the network namespace with identification number 4026540989:
mytux:~ # lsns -t net -o NS,TYPE,PATH,NPROCS,PID,PPID,COMMAND,UID,USER
NS TYPE PATH NPROCS PID PPID COMMAND UID USER
4026531963 net /proc/1/ns/net 401 1 0 /usr/lib/systemd/systemd --switched-root --system --d 0 root
4026540989 net /proc/6866/ns/net 20 6866 6864 /sbin/init 0 root
mytux:~ # ps -eo netns,pid,ppid,user,args --sort netns | grep 4026540989
4026531963 16077 4715 root grep --color=auto 4026540989
4026540989 6866 6864 root /sbin/init
4026540989 6899 6866 root /usr/lib/systemd/systemd-journald
4026540989 6922 6866 root /usr/sbin/ModemManager
4026540989 6925 6866 message+ /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
4026540989 6927 6866 tftp /usr/sbin/nscd
4026540989 6943 6866 root /usr/lib/wicked/bin/wickedd-dhcp6 --systemd --foreground
4026540989 6945 6866 root /usr/lib/wicked/bin/wickedd-dhcp4 --systemd --foreground
4026540989 6947 6866 systemd+ avahi-daemon: running [linux.local]
4026540989 6949 6866 root /usr/lib/wicked/bin/wickedd-auto4 --systemd --foreground
4026540989 6951 6866 avahi-a+ /usr/lib/polkit-1/polkitd --no-debug
n4026540989 6954 6866 root /usr/lib/systemd/systemd-logind
4026540989 6955 6866 root login -- root
4026540989 6967 6866 root /usr/sbin/wickedd --systemd --foreground
4026540989 6975 6866 root /usr/sbin/wickedd-nanny --systemd --foreground
4026540989 7032 6866 root /usr/lib/accounts-daemon
4026540989 7353 6866 root /usr/sbin/cupsd -f
4026540989 7444 6866 root /usr/lib/postfix/master -w
4026540989 7445 7444 postfix pickup -l -t fifo -u
4026540989 7446 7444 postfix qmgr -l -t fifo -u
4026540989 7463 6866 root /usr/sbin/cron -n
4026540989 7507 6866 root /usr/lib/systemd/systemd --user
4026540989 7511 7507 root (sd-pam)
4026540989 7514 6955 root -bash
If you work a lot with LXC containers it my be worth writing some clever bash or python-script for analyzing the “/proc”-directory with adjustable filters to achieve a customizable overview over processes attached to certain namespaces or containers.
Hint regarding the NS values in the following examples:
The following examples have been performed on different systems or after different start situations of one and the same system. So it makes no sense to compare all NS values between different examples – but only within an example.
Create a shell inside a new network namespace with the “unshare” command …
For some simple experiments it would be helpful if we could create a process (as a shell) with its own network-namespace. For this purpose Linux provides us with the command “unshare” (again with a lot of options, which you should look up).
For starting a new bash with a separate net-ns we use the option “-n“:
mytux:~ # unshare -n /bin/bash
mytux:~ # lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026531963 net 398 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 24
4026540989 net 21 5284 root /sbin/init
4026541186 net 2 27970 root /bin/bash
mytux:~ # ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
mytux:~ # exit
exit
mytux:~ # ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether d7:58:88:ab:cd:ef brd ff:ff:ff:ff:ff:ff
....
....
Obviously, it is not possible to see from the prompt that we have entered a different (network) namespace with the creation of the new shell. We shall take care of this in a moment. For the time being, it may be a good idea to issue commands like
lsns -t net -p 1; lsns -t net -p $$
in the shell opened with “unshare”. However, also our look at the network interfaces proved that the started “bash” was directly associated with a different net-ns than the “parent” bash. In the “unshared” bash only a “lo”-device was provided. When we left the newly created “bash” we at once saw more network devices (namely the devices of the host).
Note: A namespace (of any type) is always associated with at least one process. Whenever we want to create a new namespace for an experiment we have to combine it with a (new) process. During the experiments in this post series we will create new network namespaces together with related simple bash-processes.
And: A namespace lives as long as the associated process (or processes). To keep a specific new network namespace alive for later experiments we put the associated basic bash-process into the background of the host-system.
In real world scenarios the processes related to namespaces are of course more complex than a shell. Examples are containers, browser-processes, etc. This leads us to the question whether we can “enter” an existing namespace somehow (e.g. with a shell) to gather information about it or to manipulate it. We will answer this question in a minute.
Information about host processes from a shell inside a specific network namespace?
You can get information about all processes on a host from any process with a specific network namespace – as long as the PID namespace for this process is not separated from the PID namespace of the host. And as long as we have not separated the UID namespaces: root in a network namespace then is root on the host with all the rights there!
Can a normal unprivileged user use “unshare”, too?
Yes, but his/her UID must be mapped to root inside the new network namespace. For this purpose we can use the option “-r” of the unshare command; see the man pages. Otherwise: Not without certain measures – e.g. on the sudo side. (And think about security when using sudo directives. The links at the end of the article may give you some ideas about some risks.)
You may try the following commands (here executed on a freshly started system):
myself@mytux:~> unshare -n -r /bin/bash
mytux:~ # lsns -t net -t user
NS TYPE NPROCS PID USER COMMAND
4026540842 user 2 6574 root /bin/bash
4026540846 net 2 6574 root /bin/bash
mytux:~ #
Note the change of the prompt as the shell starts inside the new network namespace! And “lsns” does not give us any information on the NS numbers for net and user namespaces of normal host processes!
However, on another host terminal the “real” root of the host gets:
mytux:~ # lsns -t net -t user
NS TYPE NPROCS PID USER COMMAND
4026531837 user 382 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 24
4026531963 net 380 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 24
4026540842 user 1 6574 myself /bin/bash
4026540846 net 1 6574 myself /bin/bash
There, we see that the user namespaces of the unshared shell and other host processes really are different.
Open a shell for a new named network namespace
The “unshare” command does not care about “named” network namespaces. So, for the sake of completeness: If you like to or must experiment with named network namespaces you may want to use the “ip” command with appropriate options, e.g.:
mytux:~ # ip netns add mynetns1
mytux:~ # ip netns exec mynetns1 bash
mytux:~ # lsns -o NS -t net -p $$
NS
4026541079
mytux:~ # exit
mytux:~ # lsns -o NS -t net -p $$
NS
4026531963
mytux:~ #
“mynetns1” in the example is the name that I gave to my newly created named network namespace.
How to open a shell for an already existing network namespace? Use “nsenter” …
Regarding processes with their specific namespaces or LXC containers: How can we open a shell that is assigned to the same network namespace as a specific process? This is what the command “nsenter” is good for. For our purposes the options “-t” and “-n” are relevant (see the man pages). In the following example we first create a bash shell (PID 15150) with a new network namespace and move its process in the background. Then we open a new bash in the foreground (PID 15180) and attach this bash shell to the namespace of the process with PID 15150:
mylx:~ # unshare -n /bin/bash &
[1] 15150
mylx:~ # lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026531963 net 379 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 24
4026540983 net 23 4634 root /sbin/init
4026541170 net 1 15150 root /bin/bash
[1]+ Stopped unshare -n /bin/bash
mylx:~ # nsenter -t 15150 -n /bin/bash
mylx:~ # ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
mylx:~ # echo $$
15180
mylx:~ # lsns -t net -p $$
NS TYPE NPROCS PID USER COMMAND
4026541170 net 3 15150 root /bin/bash
mylx:~ #
Note, again, that “lsns” only gives you the lowest process number that opened a namespace. Actually, we are in a different bash with PID “15180”. If you want to see all process using the same network namespace you may use :
mylx:~ # echo $$ 15180 mylx:~ # ps -eo pid,user,netns,args --sort user | grep 4026541170 15150 root 4026541170 /bin/bash 15180 root 4026541170 /bin/bash 16284 root 4026541170 ps -eo pid,user,netns, args --sort user 16285 root 4026541170 grep --color=auto 4026541170
Note that the shell created by nsenter is different from the shell-process we created (with unshare) as the bearing process of our namespace.
In the same way you can create a shell with nsenter to explore the network namespace of a running LXC container. Let us try this for an existing LXC container on system “mylx” with PID 4634 (see above: 4026540983 net 23 4634 root /sbin/init).
mylx:~ # nsenter -t 4634 -n /bin/bash
mylx:~ # ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
13: eth0@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:a3:22:b8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
mylx:~ # exit
exit
Obviously, an ethernet device eth0 exists in this container. Actually, it is an interface of a veth device with a peer interface “if14”; see below.
Change the hostname part of a shell’s prompt in a separate network namespace
We saw that the prompt of a shell in a separate network namespace normally does not indicate anything about the namespace environment. How can we change this? We need 2 steps to achieve this:
- We open a shell in the background not only for a separate network namespace but also for a different uts namespace. Then any changes to the hostname inside the uts namespace for the running background process will have no impact on the host.
- The “nsenter” command does not only work for shells but for any reasonable command. Therefore, we can also apply it for the command “hostname”.
Now, before we enter the separate namespaces of the process with yet another shell we can first change the hostname in the newly created uts namespace:
mytux:~ # unshare --net --uts /bin/bash &
[1] 25512
mytux:~ # nsenter -t 25512 -u hostname netns1
[1]+ Stopped unshare --net --uts /bin/bash
mytux:~ # echo $$
20334
mytux:~ # nsenter -t 25512 -u -n /bin/bash
netns1:~ #
netns1:~ # lsns -t net -t uts -p $$
NS TYPE NPROCS PID USER COMMAND
4026540975 uts 3 25512 root /bin/bash
4026540977 net 3 25512 root /bin/bash
netns1:~ # exit
mytux:~ # hostname
mytux
Note the “-u” in the command line where we set the hostname! Note further the change of the hostname in the prompt! In more complex scenarios, this little trick may help you to keep an overview over which namespace we are currently working in.
veth-devices
For container technology “veth” devices are of special importance. A veth device has two associated Ethernet interfaces – so called “peer” interfaces. One can imagine these interfaces like linked by a cable on OSI level 2 – a packet arriving at one interface gets available at the other interface, too. Even if one of the interfaces has no IP address assigned.
This feature is handy when we e.g. need to connect a host or a virtualized guest to an IP-less bridge. Or we can use veth-devices to uplink several bridges to one another. See a former blog post
Fun with veth devices, Linux virtual bridges, KVM, VMware – attach the host and connect bridges via veth
about these possibilities.
As a first trial we will assign the veth device and both its interfaces to one and the same network namespace. Most articles and books show you how to achieve this by the use of the “ip” command with an option for a “named” namespace. In most cases the “ip” command would have been used to create a named net-ns by something like
ip netns add NAME
where NAME is the name we explicitly give to the added network namespace. When such a named net-ns exists we can assign an Ethernet interface named “ethx” to the net-ns by:
ip link set ethx netns NAME
However, in all our previous statements no NAME for a network namespace has been used so far. So, how to achieve something similar for unnamed network namespaces? A look into the man pages helps: The “ip” command allows the introduction of a PID together with the option parameter “netns” at least for the variant “ip link set”. Does this work for veth devices and the command “ip link add”, too? And does it work for both Ethernet interfaces?
In the example discussed above we had a namespace 4026541170 of process with PID 15180. We open a bash shell on our host mylx, where PID 15150 still runs in the background, and :
mylx:~ # echo $$
27977
mylx:~ # lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026531963 net 393 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 24
4026540983 net 23 4634 root /sbin/init
4026541170 net 1 15150 root /bin/bash
mylx:~ # ip link add veth1 netns 15150 type veth peer name veth2 netns 15150
mylx:~ # nsenter -t 15150 -n /bin/bash
mylx:~ # echo $$
28350
mylx:~ # ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth2@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 8e:a0:79:28:ae:12 brd ff:ff:ff:ff:ff:ff
3: veth1@veth2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether fa:1e:2c:e3:00:8f brd ff:ff:ff:ff:ff:ff
mylx:~ #
Success! Obviously, we have managed to create a veth device with both its 2 interfaces inside the network namespace associated with our background process of PID 15150.
The Ethernet interfaces are DOWN – but this was to be expected. So far, so good. Of course it would be more interesting to position the first veth interface in one network namespace and the second interface in another network namespace. This would allow network packets from a container to cross the border of the container’s namespace into an external one. Topics for the next articles …
Summary and outlook on further posts
Enough for today. We have seen how we can list (network) namespaces and associated processes. We are able to create shells together with and inside in a new network namespace. And we can open a shell that can be attached to an already existing network namespace. All without using a “NAME” of the network namespace! We have also shown how a veth device can be added to a specific network namespace. We have a set of tools now, which we can use in more complicated virtual network experiments.
In the next post
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – II
I shall present a virtual network environment for several interesting experiments with network namespaces – or containers, if you like. Further articles will discuss such experiments step by setp.
Addendum, 25.03.2024: I have started a new series about virtual networking experiments concerning veths with VLAN-interfaces, namespaces, routes, ARP, ICMP and security aspects. If you are interested in these topics a look at the posts in the new series may give you some more information on specific topics.
Links
Introduction into network namespaces
http://www.linux-magazin.de/ Ausgaben/ 2016/06/ Network-Namespaces
Using unshare without root-privileges
https://unix.stackexchange.com/ questions/ 252714/ is-it-possible-to-run-unshare-n-program-as-an-unprivileged-user
https://bbs.archlinux.org/viewtopic.php?id=205240
https://blog.mister-muffin.de/ 2015/10/25/ unshare-without-superuser-privileges/