
The topics of this blog post series are
- the basic handling of network namespaces
- and virtual networking between different network namespaces.
One objective is a better understanding of the mechanisms behind the setup for future (LXC) containers on a host; containers are based on namespaces (see the last post of this series for a mini introduction). The most important Linux namespace for networking is the so called “network namespace”.
As explained in the previous article
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – I
it is interesting and worthwhile to perform network experiments without referring to explicit names for network namespaces. Especially, when you plan to administer LXC containers with libvirt/virt-manager. You then cannot use the standard LXC tools or “ip“-options for explicit network namespace names.
We, therefore, had a look at relevant options for the ip-command and other typical userspace tools. The basic trick was/is to refer to PIDs of the processes originally associated with network namespaces. I discussed commands for listing network namespaces and associated processes. In addition, I showed how one can use shells for entering new or existing unnamed network namespaces. We finalized the first post with the creation of a veth device inside a distinct network namespace.
Advanced experiments – communication scenarios between network namespaces and groups of namespaces (or containers)
Regarding networking a container is represented by a network namespace, associated network devices and rules. A network namespace provides an isolation of the network devices assigned to this namespace plus related packet filter and routing rules from/against other namespaces/containers.
But very often you may have to deal not only with one container on a host but a whole bunch of containers. Therefore, another objective of experiments with network namespaces is
- to study the setup of network communication lines between different containers – i.e. between different network namespaces –
- and to study mechanisms for the isolation of the network packet flow between certain containers/namespaces against packets and from communication lines of other containers/namespaces or/and the host.
The second point may appear strange at first sight: Didn’t we learn that the fundamental purpose of (network) namespaces already is isolation? Yes, the isolation of devices, but not the isolation of network packet crossing the network namespace borders. In realistic situations we, in addition, need to establish and at the same time isolate communication paths in between different containers/namespaces and to their environment.
Typically, we have to address a grouping of containers/namespaces in this context:
- Different containers on one or several hosts should be able to talk to each other and the Internet – but only if these containers are members of a defined group.
- At the same time we may need to isolate the communication occurring within a group of containers/namespaces against the communication flow of containers/namespaces of another group and against communication lines of the host.
- Still, we may need to allow namespaces/containers of different groups to use a common NIC to the Internet despite an otherwise isolated operation.
All this requires a confinement of the flow of distinguished network packages along certain paths between network namespaces. Thus, the question comes up how to achieve separated virtual communication circuits between network namespaces already on the L2 level and across possibly involved virtual devices.
Veth devices, VLAN aware Linux bridges (or other types of virtual Linux switches) and VLAN tagging play a key role in simple (virtual) infrastructure approaches to such challenges. Packet filter rules of Linux’ netfilter components additionally support the control of packet flow through such (virtual) infrastructure elements. Note:
The nice thing about network namespaces is that we can study all required basic networking principles easily without setting up LXC containers.
Test scenarios – an overview
I want to outline a collection of interesting scenarios for establishing and isolating communication paths between namespaces/containers. We start with a basic communication line between 2 different network namespaces. By creating more namespaces and veth devices, a VLAN aware bridge and VLAN rules we extend the test scenario’s complexity step by step to cover the questions posed above. See the graphics below.
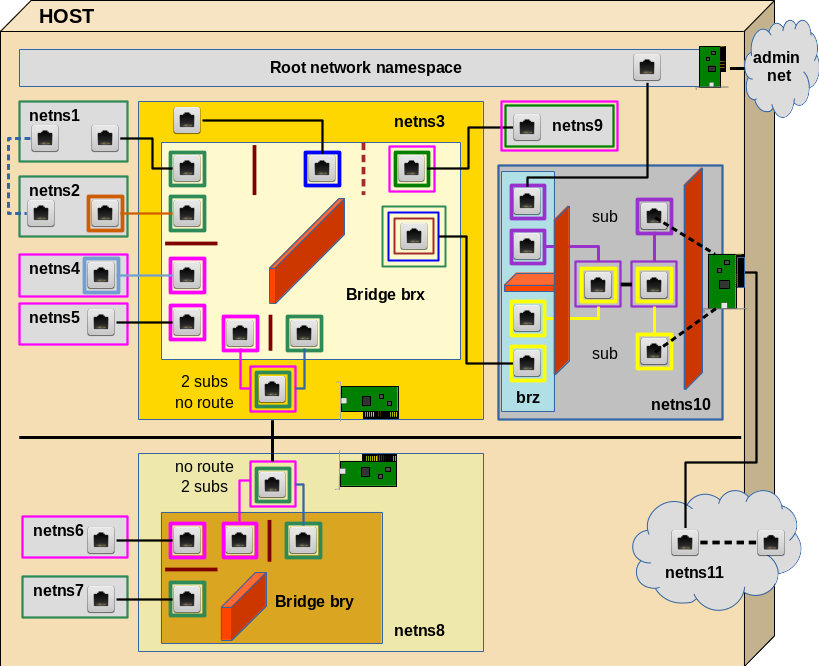
Everything actually happens on one host. But the elements of lower part (below the horizontal black line) also could be placed on a different host. The RJ45 symbols represent Ethernet interfaces of veth devices. These interfaces, therefore, appear mostly in pairs (as long as we do not define sub interfaces). The colors represent IDs (VIDs) of VLANs. Three standard Linux bridges are involved; on each of these bridges we shall activate VLAN filtering. We shall learn that we can, but do not need to tag packets outside of VLAN filtering bridges – with a few interesting exceptions.
I suggest 10 experiments to perform within the drawn virtual network. We cannot discuss details of all experiments in one blog post; but in the coming posts we shall walk through this graphics in several steps from the top to the bottom and from the left to the right. Each step will be accompanied by experiments.
I use the abbreviation “netns” for “network namespace” below. Note in advance that the processes (shells) underlying the creation of network namespaces in our experiments always establish “uts” namespaces, too. Thus we can assign different hostnames to the basic shell processes – this helps us to distinguish in which network namespace shell we operate by just looking at the prompt of a shell. All the “names” as netns1, netns2, … appearing in the examples below actually are hostnames – and not real network namespace names in the sense of “ip” commands or LXC tools.
I should remark that I did the experiments below not just for fun, but because the use of VLAN tags in environments with Linux bridges are discussed in many Internet articles in a way which I find confusing and misleading. This is partially due to the fact that the extensions of the Linux kernel for VLAN definitions with the help of Linux bridges have reached a stable status only with kernel 3.9 (as far as I know). So many articles before 2014 present ideas which do not fit to the present options. Still, even today, you stumble across discussions which claim that you either do VLANs or bridging – but not both – and if, then only with different bridges for different VLANs. I personally think that today the only reason for such approaches would be performance – but not a strict separation of technologies.
Experiments
I hope the following experiments will provide readers some learning effects and also some fun with veth devices and bridges:
Experiment 1: Connect two namespaces directly
First we shall place the two different Ethernet interfaces of a veth device in two different (unnamed) network namespaces (with hostnames) netns1 and netns2. We assign IP addresses (of the same network class) to the interfaces and check a basic communication between the network namespaces. Simple and effective!
Experiment 2: Connect two namespaces via a bridge in a third namespace
Afterwards we instead connect our two different network namespaces netns1 and netns2 via a Linux bridge “brx” in a third namespace netns3. Note: We would use a separate 3rd namespace also in a scenario with containers to get the the bridge and related firewall and VLAN rules outside the control of the containers. In addition such a separate namespace helps to isolate the host against any communication (and possible attacks) coming from the containers.
Experiment 3: Establish isolated groups of containers
We set up two additional network namespaces (netns4, netns5). We check communication between all four namespaces attached to brx. Then we put netns1 and netns2 into a group (“green”) – and netns4 and netns5 into another group (“rosa”). Communication between member namespaces of a group shall be allowed – but not between namespaces of different groups. Despite the fact that all namespaces are part of the same IP address class! We achieve this on the L2 level by assigning VLAN IDs (VIDs) to the bridge ports to which we attach netns1, netns2, em>netns2 and netns5.
We shall see how “PVIDs” are assigned to a specific port for tagging packets that move into the bridge through this port and how we untag outgoing packets at the very same port. Conclusion: So far, no tagging is required outside the Linux bridge brx for building simple virtual VLANs!
Experiment 4: Tagging outside the bridge?
Although not required we repeat the last experiment with defined subinterfaces of two veth devices (used for netns2 and netns5) – just to check that packet tagging occurs correctly outside the bridge. This is done in preparation for other experiments. But for the isolation of VLAN communication paths inside the bridge only the tagging of packets coming into the bridge through a port is relevant: A packet coming from outside is first untagged and then retagged when moving into the bridge. The reverse untagging and retagging for outgoing packets is done correctly, too – but the tag “color” outside the bridge actually plays no role for the filtered communication paths inside the bridge.
Experiment 5: Connection to a second independent environment – with keeping up namespace grouping
In reality we may have situations in which some containers of a defined group will be placed on different hosts. Can we extend the concept of separating container/namespace groups by VLAN tagging to a different hosts via two bridges? Bridge brx on the first host and a new bridge bry on the second (netns8)? Yes, we can!
In reality we would connect two hosts by Ethernet cards. We simulate this situation in our virtual environment again with a veth interface pair between "netns3" and “netns8“. But
as we absolutely do not want to mix packets of our two groups we now need to tag the packets on their way between the bridges. We shall see how to use subinterfaces of the (veth) Ethernet interfaces to achieve this. Note, that the two resulting communication paths between bridges may potentially lead to loops! We shall deal with this problem, too.
Experiment 6: Two tags on a bridge port? Members of two groups?
Now, we could have containers (namespaces) that should be able to communicate with both groups. Then we would need 2 VIDs on a bridge port for this special container/namespace. We establish netns9 for this test. We shall see that it is no problem to assign two VIDs to a port to filter the differently tagged packets going from the bridge outwards. Nevertheless we run into problems – not because of the assignment of 2 VIDs, but due the fact that we can only assign one PVID to each bridge port. This seems to limit our possibilities to tag incoming packets if we choose its value to be among the VIDS defined already on other ports. Then we cannot direct packages to 2 groups for existing VIDs.
We have to solve this by defining new additional paths inside the bridge for packages coming in through the port for netns9: We assign a PVID to the this port, which is different from all VIDs defined so far. Then we assign additional VIDs with the value of this new PVID to the ports of the members of our existing groups. An interesting question then is: Are the groups still isolated? Is pinging interrupted? And how to stop man-in-the-middle-attacks of netns9?
The answer lies in some firewall rules which must be established on the bridge! In case we use iptables (instead of the more suited ebtables) these rules MUST refer to the ports of the bridge via physdev options and IP addresses. However, ARP packets – coming from netns9 should pass to all interfaces of members of our groups.
Experiment 7: Separate the network groups by different IP address class
If we wanted a total separation of two groups we would also separate them on L3 – i.e we would assign IP addresses of separate IP address networks to the members of the different groups. Will transport across our bridges still work correctly under this condition? It should …. However, netns9 will get a problem then. We shall see that he could still communicate with both groups if we used subinterfaces for his veth interface – and defined two routes for him.
Experiment 8: Connection of container groups and the host to the Internet
Our containers/namespaces of group “green”, which are directly or indirectly attached to bridge brx shall be able reach the Internet. The host itself, too. Normally, you would administer the host via an administration network, to which the host would connect via a specific network card separate from the card used to connect the containers/namespaces to the Internet. However, what can we do, if we only have exactly one Ethernet card available?
Then some extra care is required. There are several possible solutions for an isolation of the host’s traffic to the Internet from the rest of the system. I present one which makes use of what we have learned so far about VLAN tagging. We set up a namespace netns10 with a third bridge “brz“. We apply VLAN tagging in this namespace – inside the bridge, but also outside. Communication to the outside requires routing, too. Still, we need some firewall rules – including the interfaces of the bridge. The bridge can be interpreted as an IN/OUT interface plane to the firewall; there is of course only one firewall although the drawing indicates two sets of rules.
“netns11” just represents the Internet with some routing. We can replace the Ethernet card drawn in netns10 by a veth interface to achieve a connection to netns11; the second interface inside netns11 then represents some host on the Internet. It can be simulated by a tap device. We can check, how signals move to and from this “host”.
Purely academic?
The scenarios discussed above seem to be complicated. Actually, they are not as soon as we get used to the involved elements and rules. But, still the whole setup may seem a bit academic … However, if you think a bit about it, you may find that on a development system for web services you may have
- two containers for frontend apache systems with load balancing,
- two containers for web service servers,
- two or three containers for a MySQL-systems with different types of replication,
- one container representing a user system,
- one container to simulate OWASP and other attacks on the servers and the user client.
If we want to simulate attacks on a web-service system with such a configuration on one host only, you are not so far from the scenario presented. Modern PC-systems (with a lot of memory) do have the capacity to host a lot of containers – if the load is limited.
Anyway, enough stuff for the coming blog posts … During the posts I shall present the commands to set up the above network. These commands can be used in a script which gets longer with each post. But we start with a simple example – see:
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – III