Today I upgraded a desktop PC with an Nvidia graphics card from Opensuse Leap 15.3 to Leap 15.4. I really must say: This was one of the smoothest upgrades I have ever experienced with Opensuse. However, there were again a few standard problems which had to be solved.
In this first post I summarize the upgrade steps and check the basic functionality of KDE/Plasma, VMware Workstation and KVM. I will also comment on some deficits of Plasma widgets for system monitoring.
In a second posts I summarize a brief test of Xwayland. A third post will discuss how to define a screen order for situations where multiple screens are attached to your PC. A brief fourth post will discuss PHP8 and Apache2 settings. We will also check that Eclipse works for PHP and Python/PyDeV. I will also verify the functionality of Python3 (3.9/3.10), Tensorflow2 and Jupyter after the upgrade. A last post provides solutions for multi-soundcard setups with Pulseaudio and pavucontrol.
PC components – and major SW
My PC has two major raid-systems – one with multiple SSDs (at an Intel controller, set up and controlled with the help of Linux mdraid) and one with HDs (3ware controller). The raid systems host LVM volumes and ordinary partitions. The graphics card is a relatively old Nvidia card. Two sound cards (X-Fi, Xonar D2X) are used in parallel. My standard desktop is KDE/Plasma scaled over 3 screens. For virtualization of Windows 10 VMware WS 16 is used. Virtualized Linux systems, however, run on KVM/qemu with virtual spice screens. PHP development is done with the help of Eclipse and a local Apache server. Machine Learning development is done with Python3 (3.9), PyDEV (Eclipse), Tensorflow2/Keras, Juypter.
Upgrade procedure
Regarding the basic upgrade procedure you can adapt steps which I have extensively described for a laptop here. You can just ignore any steps regarding an Optimus based combination of graphics cards.
List of steps
- Step 1:Make backups! Especially of the LVM volumes or partitions which host your root filesystem and your /home-directory.
- Step 2: Check your repositories! Save a list of your active ones and their URLs. Reason: Some repository paths below “download.opensuse.org” have changed and you need to include these repos again into zypper. Below I give some information on repositories which directly can be upgraded with the help of ${releasever}.
- Step 3: Update your current RPMs.
- Step 4: In a terminal window:
mytux:~ # zypper refresh
mytux:~ # zypper update
Then restart your system and verify that it is working.
- Step 5: In a terminal window change repo URLs to include ${releasever}
mytux:~ # sed -i 's/15.3/${releasever}/g' /etc/zypp/repos.d/*.repo
mytux:~ # sed -i 's/$releasever/${releasever}/g' /etc/zypp/repos.d/*.repo
- Step 6: In a terminal window test a refesh for the Leap 15.4 repos:
mytux:~ # zypper --releasever=15.4 refresh
If there are problems analyze the reason and eliminate those repositories whose URL have changed. Re-check the success of the refresh.
- Step 7: In a terminal window download the new RPMs
mytux:~ # zypper --releasever=15.4 dup --download-only --allow-vendor-change
- Step 8: Close the graphical desktop and switch to a TTY (Ctrl-Alt-F1). Stop the display server and then upgrade
mytux:~ # init 3
mytux:~ # zypper --no-refresh --releasever=15.4 dup --allow-vendor-change
- Step 9: Pray and reboot to your upgraded Opensuse Leap 15.4
With selected repositories discussed below all these steps could be performed without major problems.
My good news are: There were no problems regarding drivers for the Nvidia card (see below), the raid controllers and my multiple Raid 5 and Raid 10 setups with LVM groups and LVM volumes. No problem was seen regarding Grub2 and systemd.
Which repositories can be directly upgraded via ${releasever}?
Central repositories for the upgrade are
https://download.opensuse.org/update/leap/15.4/oss/
http://download.opensuse.org/update/leap/15.4/backports/
http://download.opensuse.org/update/leap/15.4/sle/
Their 15.3 precedessors must be active. You need to refresh them and replace the “15.3” in their addresses by “${releasever}”. See my post named above for the required steps. Aside of the central repositories I kept some others active during the upgrade process (with ${releasever}). Worth to name:
https://download.opensuse.org/repositories/LibreOffice:/7.5/openSUSE_Leap_15.4/
https://download.nvidia.com/opensuse/leap/15.4
https://developer.download.nvidia.com/compute/cuda/repos/opensuse15/x86_64
https://ftp.fau.de/packman/suse/openSUSE_Leap_15.4/
https://download.opensuse.org/repositories/mozilla/openSUSE_Leap_15.4/
https://download.opensuse.org/repositories/devel:/languages:/php/openSUSE_Leap_15.4/
These repositories cause no problems as their URLs for 15.3 and 15.4 only show a difference regarding their release version but not their position in the URL-tree below “download.opensuse.org”. However, some other repositories, like those for X2GO, graphics, network, security have changed their position in the URL-resource-tree and must be reconfigured after the upgrade – e.g with the help of YaST or zypper.
Nvidia driver and the new kernel
On Leap 15.3 I had used the latest Nvidia driver from the usual Nvidia community repository
download.nvidia.com/opensuse/leap/${releasever}
The active RPM was replaced by the one from the Leap 15.4 repo during upgrade resulting in the RPM “nvidia-compute-G06”, version 525.89.02-lp154.5.1. Both the transition to the respective Nvidia kernel module for the new kernel 5.14.21 and the module’s inclusion in the system’s startup procedures by dracut went without any faults.
The upgraded system directly started into a SDDM login screen. There as a mess regarding my screen order (see a forthcoming post), but this did not hinder a proper login. Afterward KDE/Plasma (in combination with Xorg) started on the three screens attached to my PC. Though I feel that the startup of KDE/Plasma for Xorg takes a more time than on Leap 15.3. But I could see no major problems. GLX applications were running as expected.
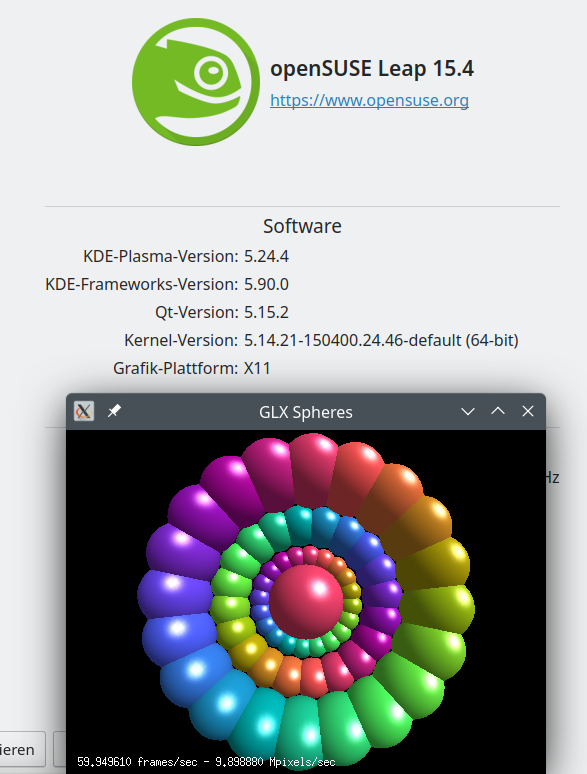
VMware Workstation WS 16.2.5 works!
As I already saw with a Leap 15.4 installation on a laptop: VMware WS 16.2.5 works with Leap 15.4 and Kernel 5.14.21. Actually, already version WS 16.2.3 is compatible.
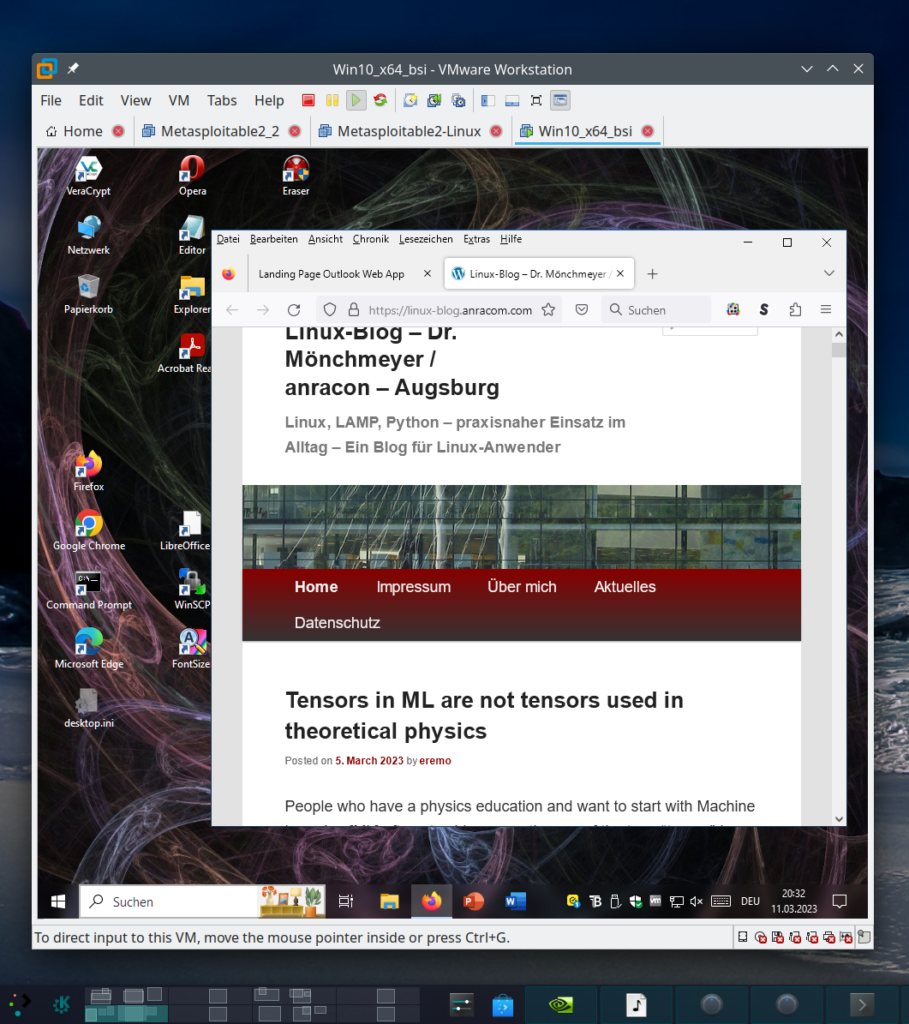
KVM/Qemu works with installed virtual systems!
The transition of KV, qemu und libvitrtd went smoothly. virt-manager works and starts installed virtual systems as expected:
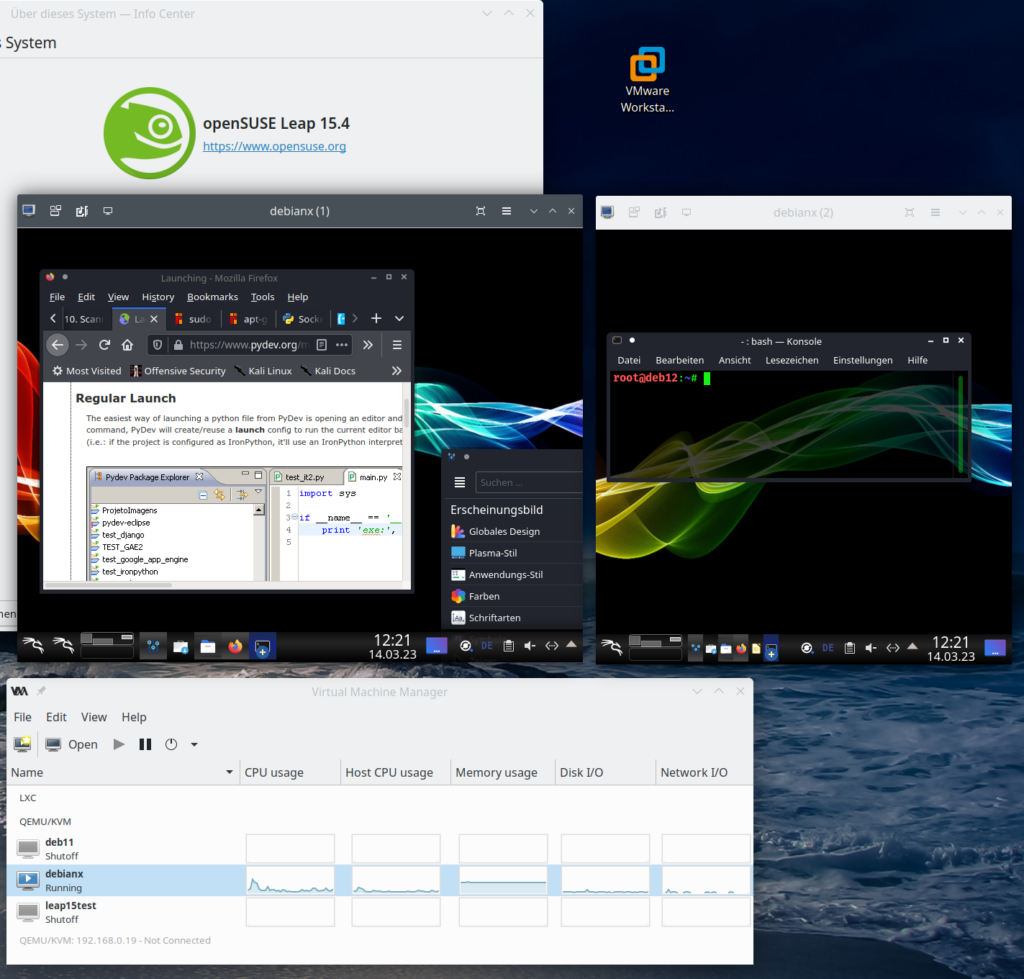
KDE – plasma-systemmonitor and respective widgets do not show information on Nvidia graphics card and not all information on network cards
At least on my system with KDE Plasma 5.24.4 (KDE Framework 5.90) I saw major deficits regarding apps and widgets which should monitor the status of system resources:
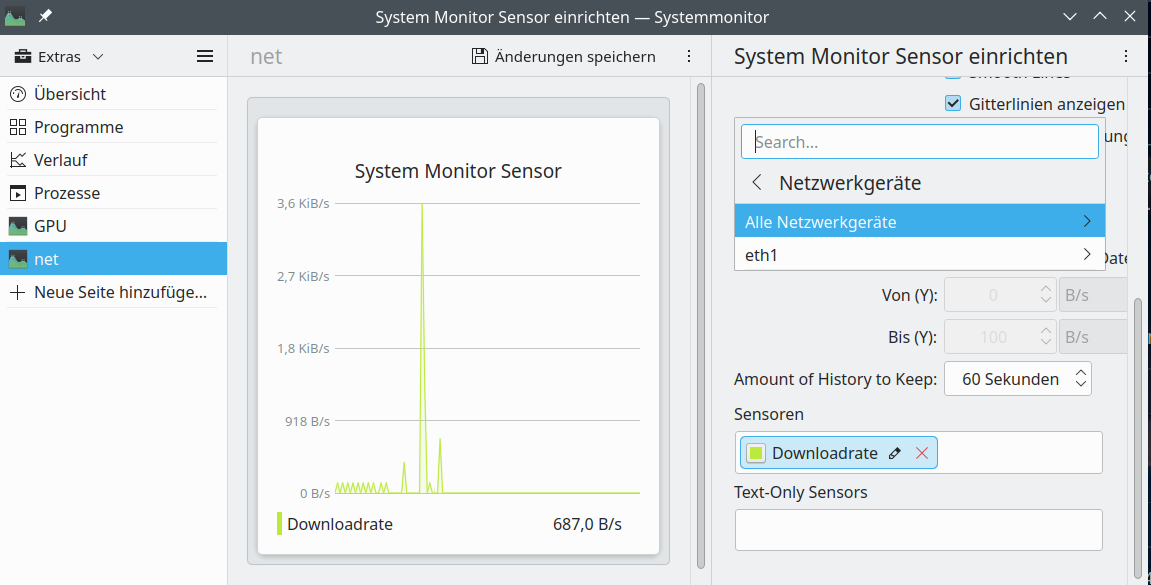
- Problem 1 – no information about the status of the Nvidia GPU: Neither the application “systemmonitor” nor related widgets can deliver information about the status of the NVidia card (temperature, VRAM usage, fan) – with the (useless) exception of the type of the card. See th eimage in the next section. (Note that lm_sensors do not help in this case as the HW sensors did not detect the Nvidia card either.)
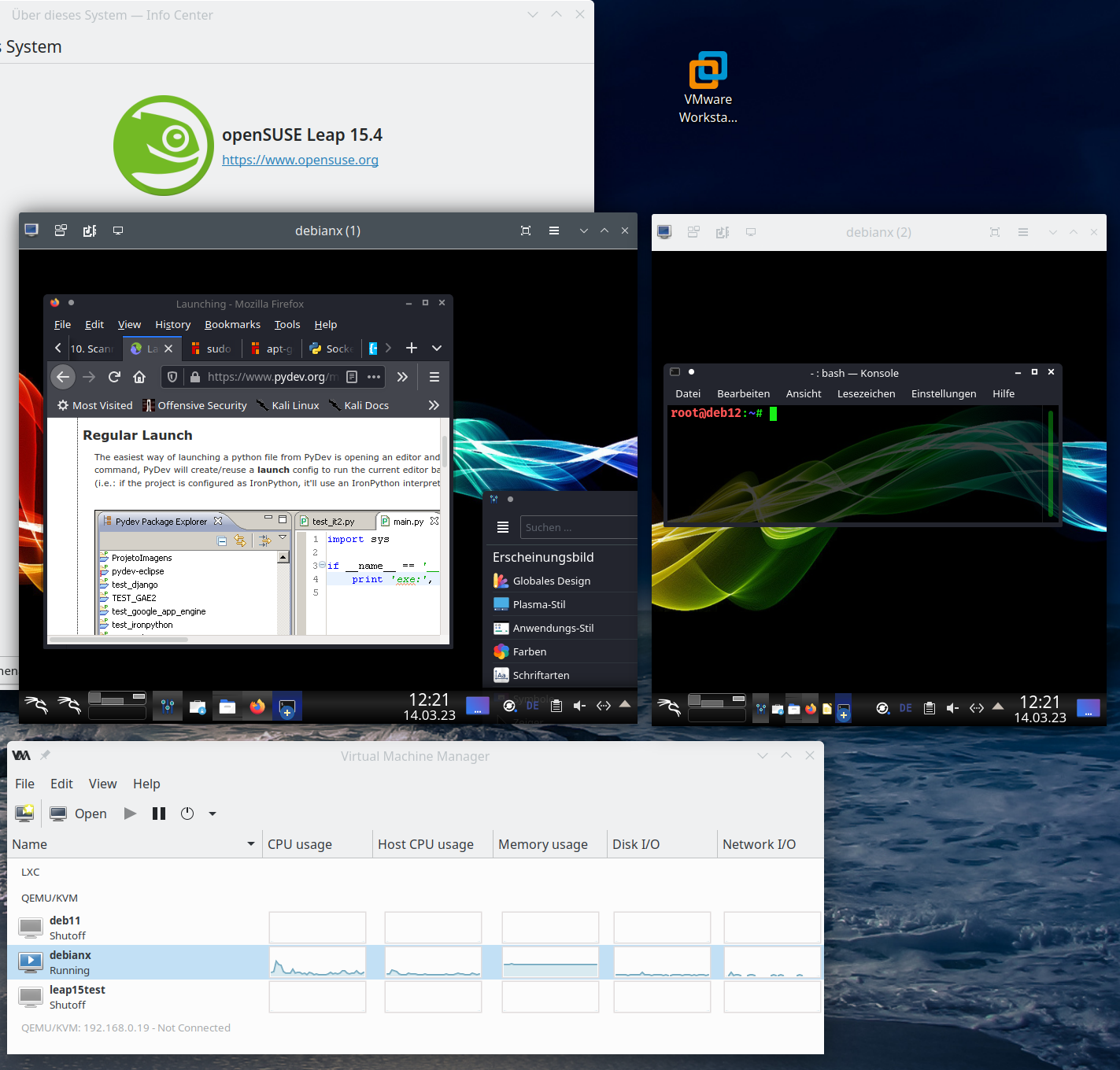
- Problem 2 – no information about virtual network devices: In addition the KDE/Plasma widgets were not able to display all data for network interfaces correctly. E.g. interfaces like lo, bridges and other virtual devices were not even listed. And thus on a more complex configuration with virtualization you will not see your IP addresses with the Plasma-tools.
Regarding the second point: The image below shows that the dialog to set up network monitoring only offers to select an active physical device, in my case eth1. But no virtual devices which are available, too.
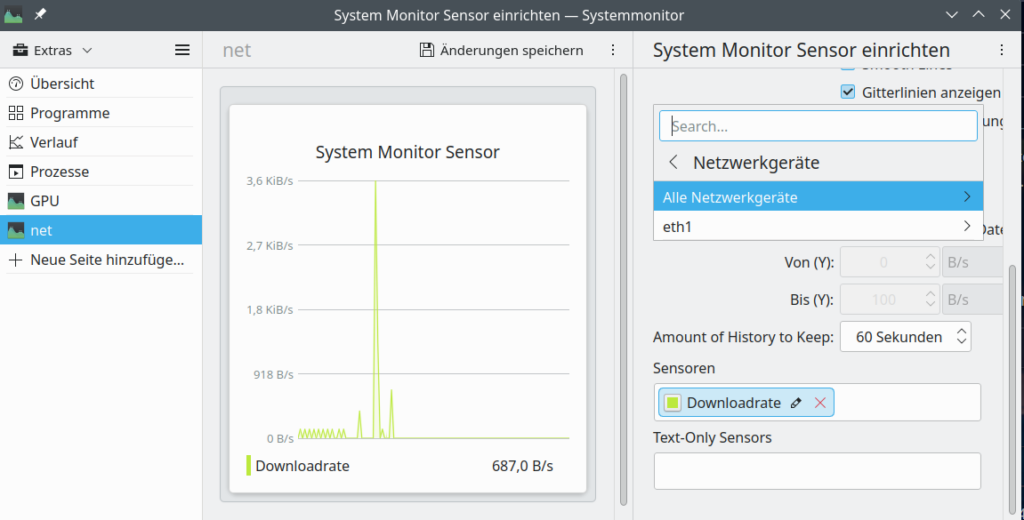
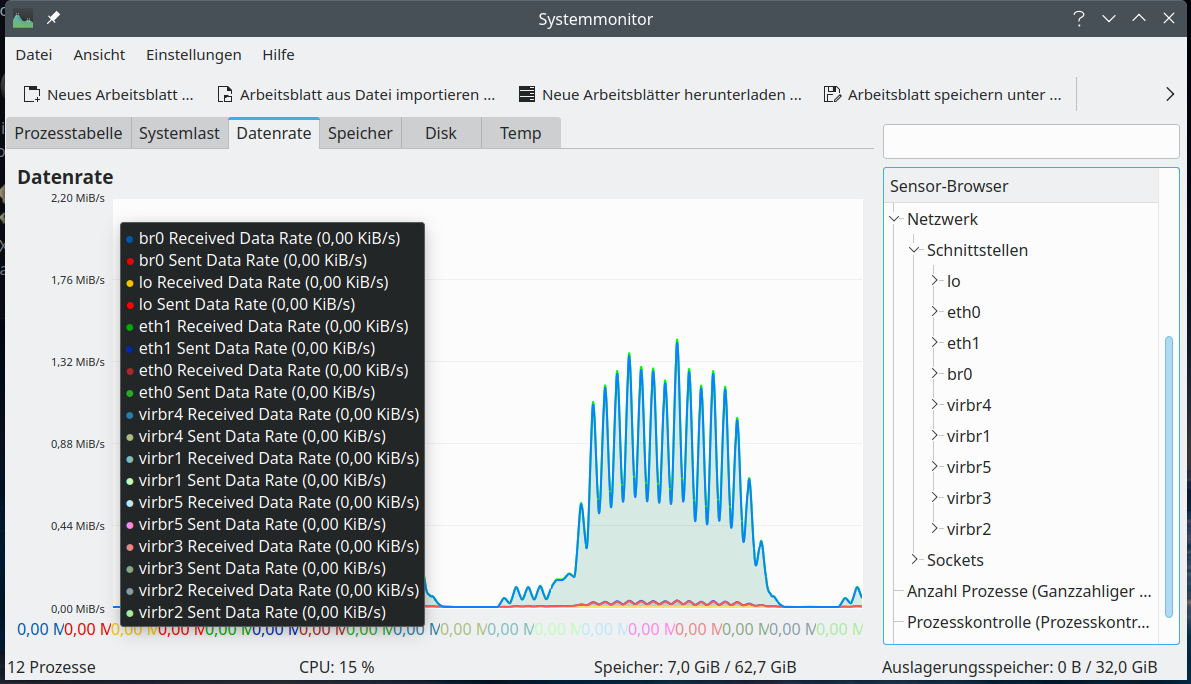
And here the devices nmon lists up:
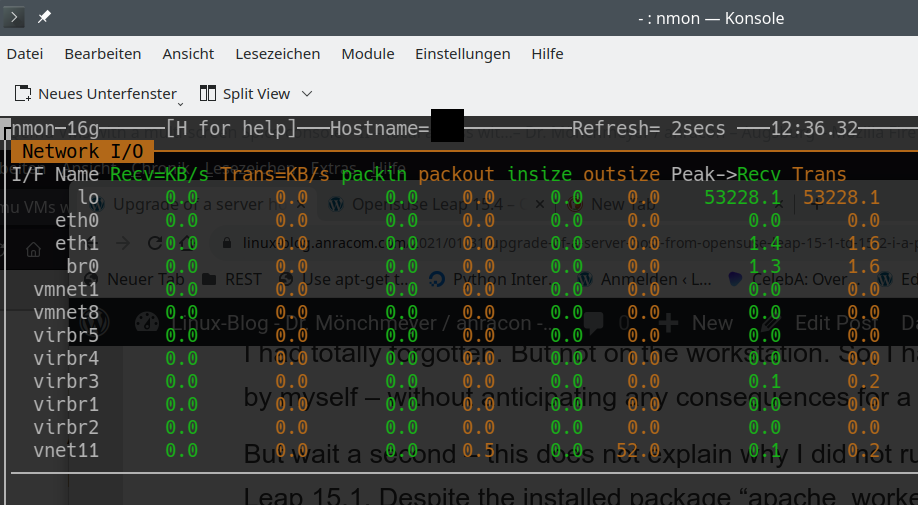
These are clearly Plasma problems as other basic Linux and desktop applications perform much better for the named resources. Someone who works with Machine Learning and with virtualized Linux installations needs to watch the GPU (fans and temperature) and traffic across network devices – virtualized or real. This does not seem to be something we can get from fancy KDE/Plasma widgets today. So, we have to look out for alternatives.
Alternatives to watch the temperature of Nvidia GPUs
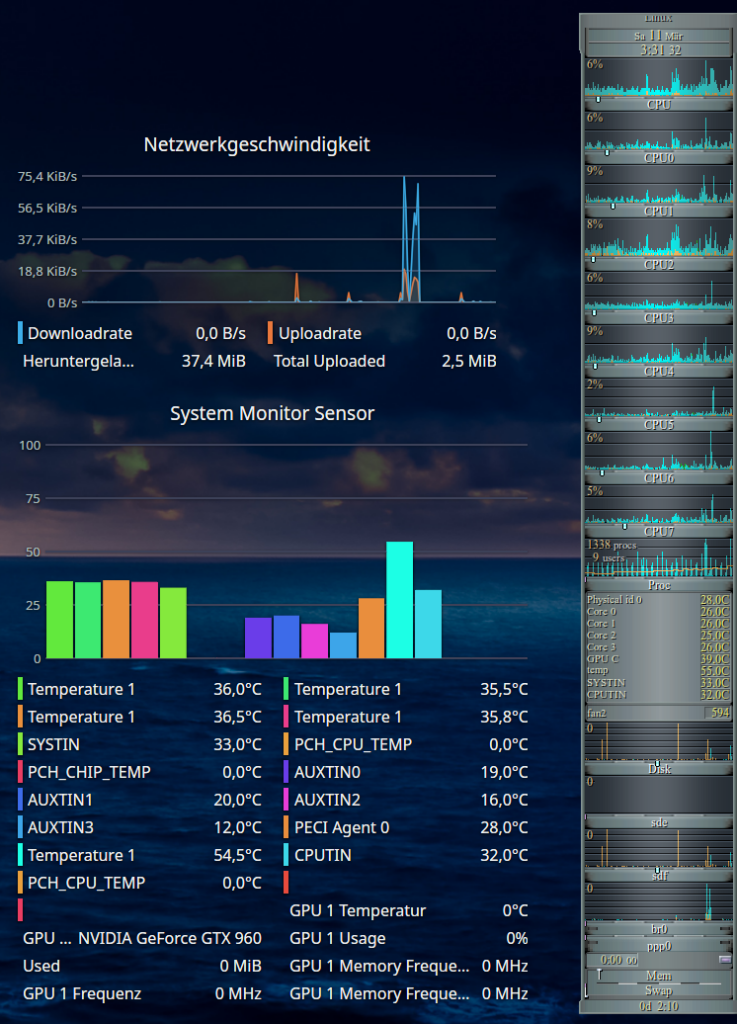
One prominent example which covers more than the present KDE widgets for system monitoring is the good old “gkrellm“. I love it, really! Compact, with a lot of already integrated default “sensors” and compatible to lm_sensors! And it delivers me the GPU temperature.
Another desktop tool with a somewhat old fashioned presentation of graphics is psensor. You can get a binary for Leap 15.4 from the “home”-repository of plasmaaregataos.
https://download.opensuse.org/repositories/home:/plasmaregataos/15.4/
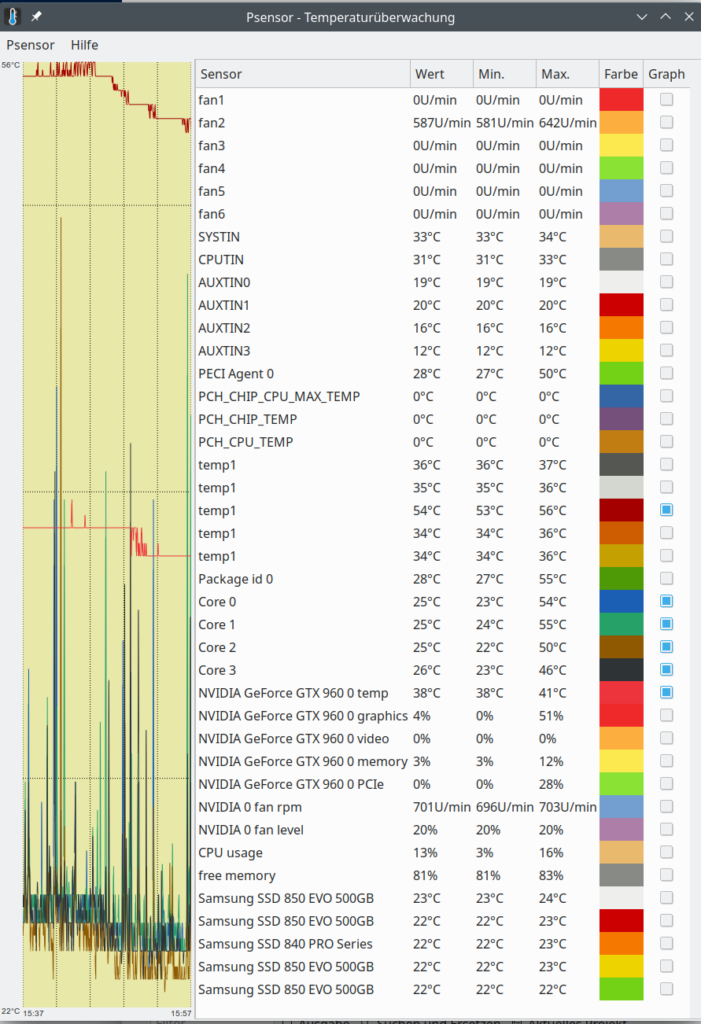
Interesting, how much this tool finds out about the Nvidia card (where Plasma tools fail totally).
And then we have, of course, Nvidia’s own tools: nvidia-settings (graphical) and nvidia-smi (ASCII):
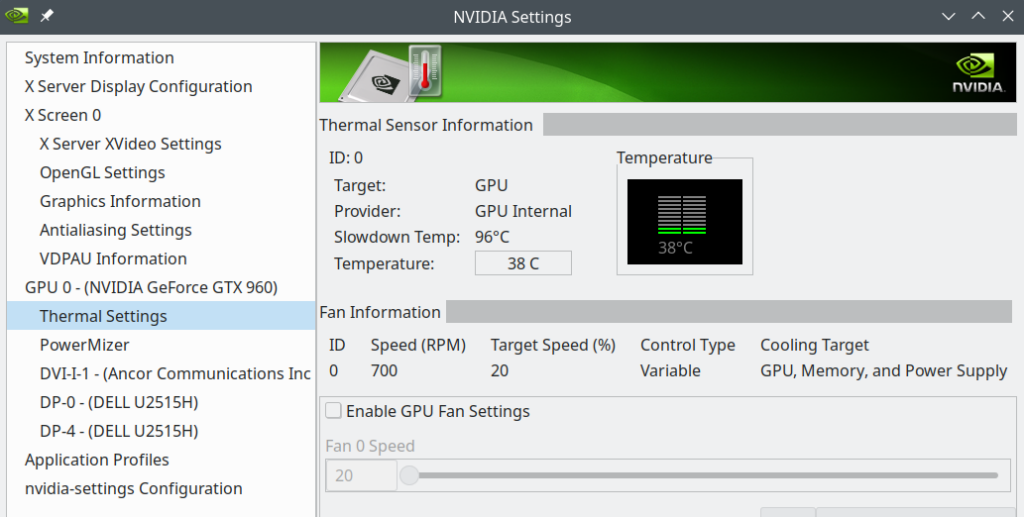
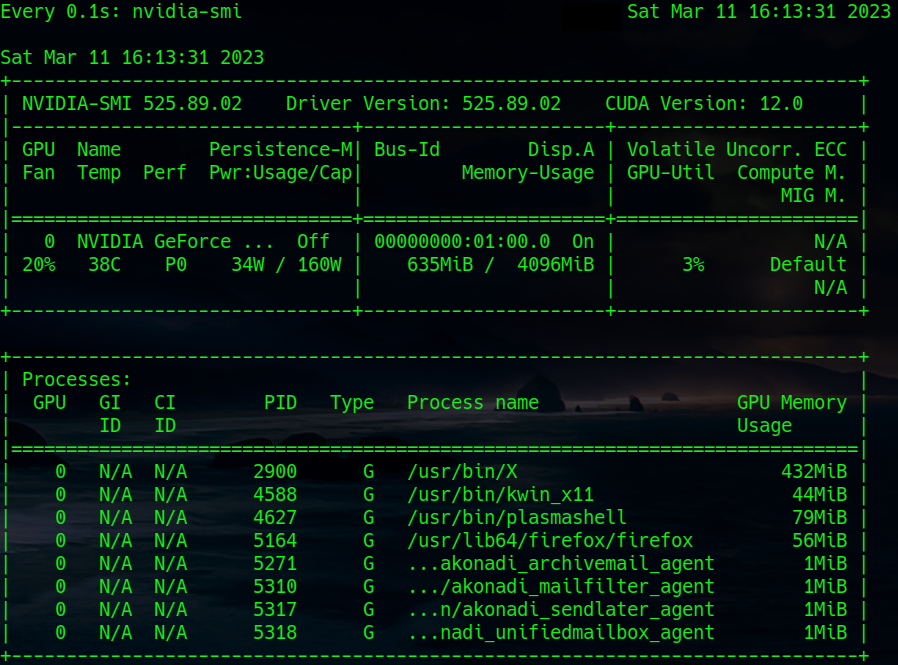
Note that the command to periodically update the nvidia-smi information is:
watch -n0.1 nvidia-smi
Alternatives to watch the data traffic across all network devices – real and virtual
Once again I have to name gkrellm. It provides a lot of information on real and virtual network interface.
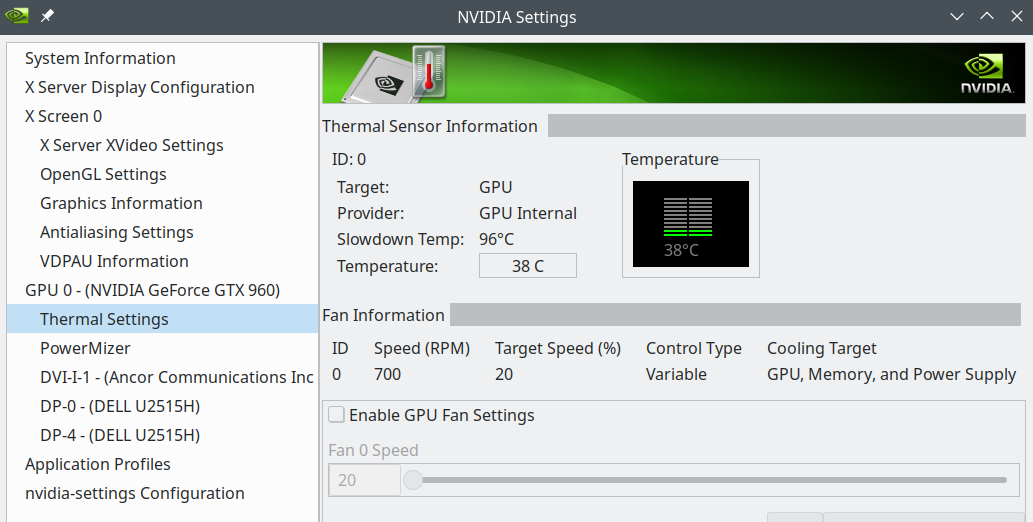
Regarding a graphical information on virtual network interfaces we can also use a relatively old KDE tool, namely ksysguard. Besides real network interfaces it detects bridges and KVM or Vmware based virtual devices and tracks their load.
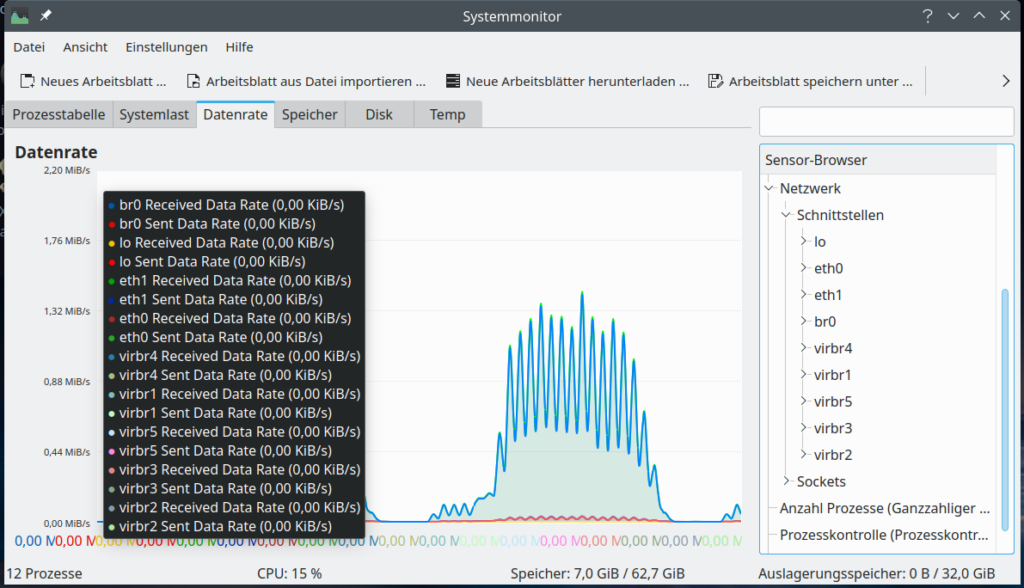
Hint for those who worry about the discrepancy with the screenshot for nmon above: Some devices which nmon showed were not available at the time of the screenshot of ksysguard as certain KVM virtual machines and networks were not yet started. Later ksysguard detects other devices, too:
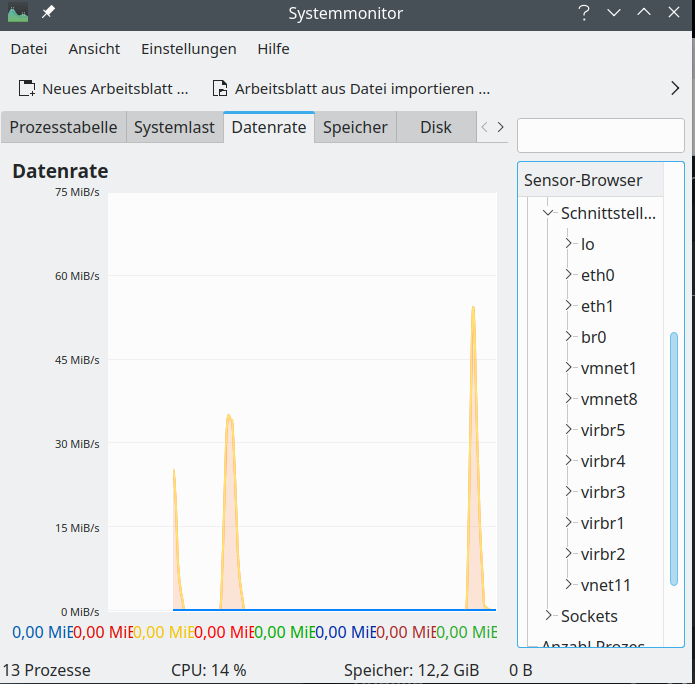
Based on ncurses you can also use the network part of “nmon” to get information on transfer rates across all defined network interfaces. If you need to go more into details a very good ASCII tool is “iptraf-ng“. “iftop” is also cool, but to watch multiple interfaces in parallel you have to use the command “iftop -i” on multiple terminal windows.
So, dear Plasma developers: When can we expect a fancy Plasma applications or widgets which reproduce and combine the “sensoric” abilities of gkrellm, psensor, ksysguard and iptraf-ng?
Conclusion
The upgrade from Leap 15.3 to Leap 15.4 posed no major problems on my PC. A relatively old VMware WS 16.2.x still worked and there were no problems regarding KVM/qemu. The new Nvidia driver could be compiled without any problems for the new kernel during upgrade and was directly integrated into the system by dracut. The new KDE/Plasma version started without problems on Xorg. Deficits of Plasma widgets for monitoring system devices were obvious; but this is not something we can blame Opensuse for.
In the next post of this series
Opensuse Leap 15.4 on a PC – II – Plasma, Gnome, flatpak, Libreoffice and others on (X)Wayland?
I will have a look at KDE/Plasma started on Xwayland.
Happy working with Opensuse Leap 15.4 and stay tuned …