we have studied the transformation of an ellipse by a shear operation. The coordinates of points on an ellipse and the components of respective position vectors fulfill a quadratic equation (quadratic form):
The superscript “T” symbolizes the transposition operation. The symmetric (2×2)-matrix \( \pmb{\operatorname{A}}_q^O \) defines the original, unsheared ellipse. The suffix “q” indicates the quadratic form. I have shown how the shear parameter λS impacts the coefficients of a corresponding (2×2)-matrix \(\pmb{\operatorname{A}}_q^S \) that defines the sheared ellipse.
What I have not done in the last post is to show how our matrix \(\pmb{\operatorname{A}}_q^S \) is related to a shear matrix \(\pmb{\operatorname{M}}_{sh} \) (see the first post), which describes the effect of the shear on the vectors \( \left(\,x_o,\, y_o\,\right)^T \). I am going to discuss this below. The given matrix relations will also be valid for general n-dimensional ellipsoids.
Matrix relations as discussed below are helpful to accelerate numerical calculations as Numpy (in cooperation with libraries for your OS) provides highly optimized modules for matrix operations. n-dimensional ellipsoids furthermore characterize hyper-surfaces of multivariate normal distributions which appear in certain areas of Machine Learning and respective data.
Matrix describing a centered n-dimensional ellipsoid
We consider n-dimensional and centered ellipsoids whose symmetry centers coincide with the origin of the Euclidean coordinate system [ECS] we work with. A position vector \(\left(\,x_1^o,\, x_2^o\, \cdots x_n^o \right)^T \)
is a vector drawn from the origin to a point on the ellipsoid’s hyper-surface. Note that a general vector of a vector space has no reference to a coordinate system’s origin. Therefore the distinction. A general ellipsoid is defined by a quadratic form in the components of its position vectors. The quadratic form is equivalent to the following matrix equation
where \(\pmb{\operatorname{A}}_{qn}^O \) now represents a symmetric (nxn)-matrix. The “\( \circ \)” symbolizes a matrix product.
Note: A coefficient \( \delta \gt 0 \) which we have used in previous posts on the right side of the equation can be included in the coefficient values of the matrix).
Note that the equations above define an ellipsoid up to a translation vector. This is reflected in the fact that the above equation does not create any linear terms.
Quadratic forms not only define ellipsoids. For an ellipsoid we have to assume that the determinant of\(\pmb{\operatorname{A}}_{qn}^O \) is > 0 and that the matrix is invertible:
Note that you could choose an ECS in which the ellipsoid’s principal axes would align with the ECS’s coordinate axes. Such a choice would correspond to a PCA-transformation of the vector data. \(\pmb{\operatorname{A}}_{qn}^O \) would then become diagonal. This corresponds to the fact that a symmetric matrix always has an eigenvalue-decomposition.
Equation of the quadratic form for the sheared ellipsoid
In the first post of this series I have defined a (invertible) shear matrix as a unipotent matrix \( \pmb{\operatorname{M}}_{sh} \) with all coefficients of the lower triangular part, off the diagonal, being equal to 0.0 and all elements on the diagonal being equal to 1:
So an inverse matrix \( \pmb{\operatorname{M}}_{sh}^{-1} \) exists. Shearing our original ellipse (with position vectors \( \pmb{x_o} \)) leads to new vectors \( \pmb{x_S} \):
Σ is a diagonal (nxm)-matrix with singular values. The column-vectors of U and V are orthogonal singular vectors. Geometrically, U and V can be interpreted s rotational operations.
Therefore, we can decompose a (nxn) upper triangular shear-matrix into two orthonormal (nxn)-matrices U and V plus a diagonal matrix Σ :
This gives us an alternative form to define the inverse shear matrix. Note that the order of the matrices in the matrix products is essential.
An example for the case of a sheared ellipse
We use the example of a sheared ellipse discussed in the last post to verify the results above numerically for a 2-dim case. To write a respective Python/Numpy-program is simple. I will just give you my numerical results below.
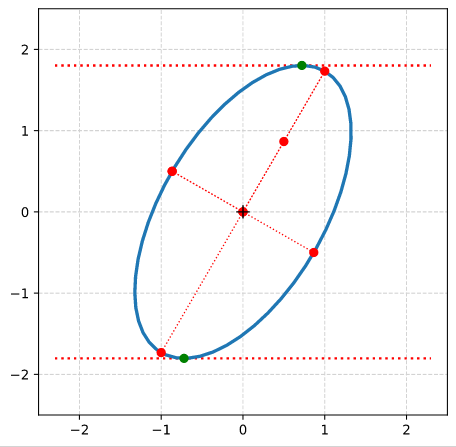
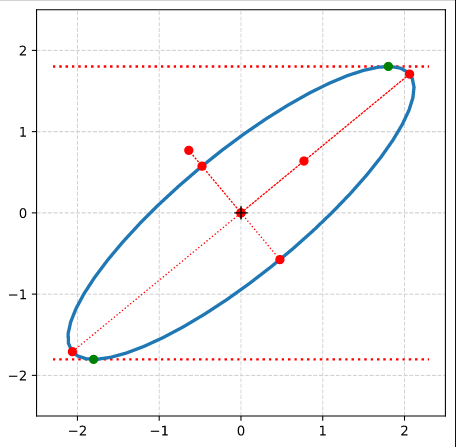
We have used an ellipse with the longer and shorter primary axes having values a = 2 and b = 1, respectively. The ellipse was rotated by 60° against the ECS-axes.
The respective (2×2)-matrix \( \pmb{\operatorname{A}}_q^O \) had the following coefficients
We have shown how a shear matrix \( \pmb{\operatorname{M}}_{sh} \) transforms the matrix \(\pmb{\operatorname{A}}_{qn}^O \) which defines an un-sheared n-dimensional ellipsoid into a matrix \(\pmb{\operatorname{A}}_{qn}^S \) defining its sheared counterpart. We have also had a glimpse on a SVD decomposition of a shear matrix. The results will enable us in the next post to apply shear operations on a concrete example of a 3-dimensional ellipsoid.
Post III focused on the shearing of a circle, which was centered in the Euclidean coordinate system [ECS] we worked with. The shear operation resulted in an ellipse with an inclination against the coordinate axes of our ECS. This was interesting regarding four points:
A circle, which is centered in a chosen ECS, exhibits a continuous rotational symmetry (isotropy). This obviously allows for a decomposition of a shear operation into a sequence of two affine operations in the chosen ECS: a scaling operation (with different factors along the coordinate axes) followed by a rotation (or the other way round). Equivalently: We could switch to another specific ECS which is already rotated by a proper angle against our originally chosen ECS and just perform a scaling operation there. The rotation angle is determined by the shear parameter λ. This seems to stand in some contrast to the shearing of figures with only discrete rotational symmetries: We saw for rectangles and cubes that an additional rotation was required to replace the shear operation by a sequence of scaling and rotation operations.
Points (x, y) of circles and ellipses are described by quadratic forms in two dimensions (with some real coefficients α, β, γ, δ):
\[
\alpha \,x^2 \, + \, \beta \, x \, y \, + \, \gamma \, y^2 \:=\: \delta
\]
Quadratic forms play a general role in the mathematical description of cone-sections. (Ellipses are the results of specific cone-sections.)
Ellipses also result from projections of multi-dimensional ellipsoids onto two-dimensional coordinate planes. Multi-dimensional ellipsoids are described by quadratic forms in an ECS covering the ℝn.
Hyper-surfaces for constant probability density values of multivariate normal vector distributions form multi-dimensional ellipsoids. Here we have a link to Machine Learning where key properties of certain objects are often ruled by Gaussian distributions.
From the first point we may expect that a shear operation applied to a multi-dimensional sphere will result in a multi-dimensional ellipsoid – and that such an operation could be replaced by scaling the original sphere (with different factors along n coordinate axes of a n-dimensional ECS) followed by a rotation (or vice versa). We will explicitly investigate this for a 3-dimensional sphere in the next post.
If our assumption were true we would get a first glimpse of the fact that a general multivariate standard distribution can be created by applying a sequence of distinct affine (i.e. linear) operations to a spherical probability distribution. This is discussed in detail in another post-series in this blog.
What is a bit confusing at the moment is that a replacement of a shear operation by simpler affine operations in general seems to require at least two rotations, but only one when we work with centered isotropic bodies. We come back to this point when we discuss the decomposition of a shear matrix by the so called SVD-procedure.
In the previous post of this series we have used the radius of the circle and the shearing parameter λ to derive analytical expressions for the coordinates of special points with extremal values on our ellipse
Points with maximal and minimal y-coordinate values.
Points with a maximal or minimal distance to the symmetry center of the ellipse. I.e. the end-points of the principal diameters of the ellipse.
From the fact that shearing does not change extremal values along the axis perpendicular to the sharing direction we could easily determine the lengths of the ellipse’s principal axes and the inclination angle of the longer axis with the x-axis of our Euclidean coordinate system [ECS].
What do we have in addition? In another mini-series on ellipses
I have meanwhile described how the geometry of an ellipse is related to its quadratic form and respective coefficients of a symmetric matrix. I call this matrix Aq. It forces the components of position vectors to fulfill an equation based on a quadratic polynomial. Furthermore Aq‘s eigenvalues and eigenvectors define the lengths of the ellipse’s principal axes and their inclination to the axes of our chosen ECS. The matrix coefficients in addition allow us to determine the coordinates of the points with extremal y-values on an ellipse. We will use these results later in the present post.
Objectives of this post: Shearing of a centered, rotated ellipse
In this post I want to show that shearing a given centered, but rotated original ellipse EO results in another ellipse ES with a different inclination angle and different sizes of the principal axes.
In addition we will derive the relations of the shearing parameter λS with the coefficients of the symmetric matrix \(\pmb{\operatorname{A}}_q^S \) that defines ES. I also provide formulas for the dependence of ES‘s geometrical properties on the shear parameter λS.
There are two basic prerequisites:
We must show that the application of a shear transformation to the variables of the quadratic form which describes an ellipse EO results in another proper quadratic form and a related matrix \(\pmb{\operatorname{A}}_q^S \).
The coefficients of the resulting quadratic form and of \(\pmb{\operatorname{A}}_q^S \) must fulfill a mathematical criterion for an ellipse.
We expect point 1 to be valid because a shear operation is just a linear operation.
To get some exercise we approach our goals by first looking at the simple case of shearing an axis-parallel ellipse before extending our considerations to general ellipses with an inclination angle against the coordinate axes of our chosen ECS.
This post requires Javascript to display formulas!
In Machine Learning samples of data vectors often undergo linear transformations. Typical examples are the adaption of vector component values due to the choice of a different shifted and/or rotated coordinate system. Another example is the scaling of vectors. As we have seen in an investigation of Autoencoders they produce multivariate normal distributions which actually are the result of linear transformations of elementary Gaussian distributions. And let us not forget that the transport between layers of neural networks includes linear transformations.
In most cases we can interpret a linear transformations in the ℝn in a geometrical way. Linear transformations are members of a sub-class of affine transformations. Affine transformations in turn can be regarded as a combination of
a translation,
a scaling in either coordinate direction,
a reflection = mirroring operation,
a rotation
and/or a shear operation.
Translations are trivial. We also understand the effects of rotation and scaling transformations intuitively. A mirror operation can be understand as a kind of inverted scaling with factors -1.
Scaling operations with different scaling factors along different coordinate directions destroy certain rotational symmetries of a 3-dimensional or n-dimensional body. But scaling transformations do not always eliminate symmetries with respect to mirroring planes: If and when we first choose an Euclidean coordinate system whose axes are aligned with symmetry axes of a body with plane symmetries, we are able to keep up at least some of the planar symmetries of the body during scaling operation.
Something that is a bit more difficult to grasp is a shear operation. The reason is that a shear operation destroys one or multiple plane symmetries of an impacted figure – whatever coordinate system we choose. And a shear operation cannot be reduced to a pure scaling operation in some cleverly chosen coordinate system. Neither can it be reduced to a rotation.
This alone is a good reason to have a closer look at this special kind of affine transformation. Another reason is to study what impact a shear operations has on the construction or transformation of a multivariate normal distribution – a topic which is at the center of another post series in this blog.
In this post I first want to discuss what a matrix that controls a shear operation looks like. We discuss some of its mathematical properties. Afterward I want to demonstrate what effects shearing has on two simple objects – a cube and a sphere. These examples will be done with Blender and the available mouse driven shear operations there.
Blender performs the required math in the background – and the examples below only provide visual impressions.
To get a better understanding of the nature of shear operation we, in the second post of this series, switch to Python and apply shear operations via explicit matrix operations onto vectors. We start with 2D-figures. Afterward we turn to 3D-cuboids and find that we produce spats. Another important example (not only with respect to multivariate normal distributions) is then given by the shearing of 3D-spheres: We will find that such an operation always produce ellipsoids. We will check this mathematically.
In a fourth post I want to discuss an important result from linear algebra, namely the so called SVD-decomposition of a linear transformation and its meaning in our context of shear operations. SVD tells us that we can always replace a shear operation by a sequence of simpler operations. We will test this statement for our 2D- and 3D-objects objects. We then also find that the creation of an ellipsoid at any orientation can be done by applying just one shear operation to a unit sphere. Alternatively, we can perform a scaling of a sphere and rotate it once. This will help us to better understand the creation of multivariate normal distributions in a parallel post series.
Shear operations break symmetries of the affected figures
A shear operation Msh introduces an asymmetry into originally symmetric figures. It does so by coupling vector components in a specific way. For reasons of simplicity we reduce our argumentation to the ℝn. We describe objects in this space with the help of position vectors to points inside and on the surface of these objects. We specify the components of position vectors with respect to an Euclidean coordinate system [ECS].
To make things easier we assume that the origin of our ECS coincides with the symmetry center of the body we apply the shear operation to. If the body has plane and point symmetries then the origin is placed at the cutting lines or the cutting point of such planes; i.e., the ECS origin coincides with the symmetry-center of the body and coordinate planes will coincide with some of the symmetry planes. For the cases we look at – spheres, cubes, coboids – the ECS origin thus gets identical with the body’s volume center.
A shear transformation applied to a vector couples at least two of the vector’s components such that a growing value for the coordinate value in the direction of a chosen coordinate axis (e.g. vz) impacts the coordinate value in another coordinate direction (e.g. vx) in a linear way.
Here is an example for the x- and z-components of a 3-dimensional vector (vx, vy, vz)T:
With α being some constant. This operation breaks an original plane symmetry of a body with respect to the x-z-plane.
A shear operation preserves the orientation of tangent planes at some surface points
But note also, that a shear operation has another unique property that keeps up a geometrical property of the affected body:
A shear operation preserves the orientation of tangent planes to the body’s surface at some particular points. The most important of these points define extrema on the surface with respect to the component whose value is linearly added in the shearing transformation. The tangent planes there do not only keep up their orientation, but also their position.
In the case defined above we would look a extrema with respect to the z-component:
\[ z \,=\, f(x,\,y), \quad { \partial f \over \partial x } \,=\, { \partial f \over \partial y } \, = \, 0
\]
Actually, we would need a bit of multivariate calculus to derive this statement for general bodies. But the example of a cube helps to grasp the central point: The transformation defined above would keep up the orientation and position of the top and the bottom square surfaces of the cube. See below for respective graphics.
In the case of a general n-dimensional body whose surface is closed, continuous and differentiable at all surface points we will find at least two such points whose tangent planes keep their orientation and position during a shearing operation.
Coupling of more than two vector components – and a restriction
Of course we could have introduced more than just one linear coupling of a selected vector component to other components. In three or n dimensions we can couple 2 components to a third one. In n dimensions we can add up shearing contributions of (n-1)-coordinate values to each of the components. But we introduce a restriction:
To avoid confusion and double shearing effects we always set αzx = 0. And analogously for the other components:
Once again: We avoid a kind of double coupling between the same pair of components. E.g., vx may become impacted by vz, but vz then shall not get impacted by vx at the same time.
Obviously, this is a an asymmetric policy in the formal handling of vector component coupling. But, it has geometrical consequences (see below). Of course, we follow this asymmetric policy also for other pairs of vector components and respective coupling parameters. This gives us a number of n*(n – 1)/2 potential constant shearing parameters.
A first example produced with the help of Blender
To get a visual impression of what shearing does to a body with some symmetries, let us look at a simple example: a cube.
Regarding the first image we define that the x-coordinate direction goes from the left to the right, the y-direction from the front to the back and the z-direction from the bottom vertically upwards. The last image from the top shows that the x- and y-side-length of our cube are equal. Among other symmetries, a cube and also cuboids obviously have a mirror symmetry with respect to planes parallel to the x/y-plane, the y/z-plane and the x/z-plane through their centers of volume.
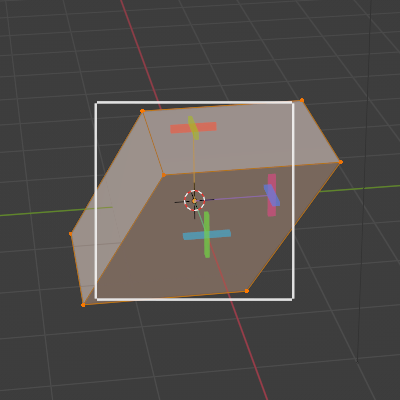
Now let us apply two shear operations which couple the x/z-coordinates and the y/z-coordinates. Then we get something like the following:
The first two image show the sheared object from the front, but with the camera moved to different heights. We see that the cube was sheared in two directions – in the x- and in the y-direction. The z-values of the upper and lower surfaces remain constant during the operation. As a result the object gets inclined in two directions: We get a spat (or parallelepiped) as the result of applying a shear operation to a cube or cuboid.
The last image shows the object from exactly the same top position as before the shearing. We see that the original symmetry is destroyed with respect to all 3 orthogonal planes (parallel to coordinate planes) through the center of volume of our object.
Also all of the following objects are the results of simple shearing operations. While this clear for the parallelepiped (derived from a cuboid) and the inclined cylinder (derived from a straight cylinder), it is not directly obvious for the ellipsoid which in the depicted case actually is the result of a shearing applied to a sphere (with x being impacted by y and z). In all cases rotations and translations have been applied in addition to arrange the scene.
We get the impression that some simple geometric shapes like a spat or an ellipsoid could be the direct result of one or more shearing operations applied to originally simple objects with multiple symmetries – as cubes and spheres.
Shear transformations are mathematically done by unipotent upper triangular matrices
Let us return to a more mathematical description of a shear operation. As any other linear operation applied to vectors of the ℝn we can represent a shear operation by a matrix. We just have to express the linear coupling between two vector components by a suitable arrangement of our shear-constants as matrix-elements. By experimenting a bit we find that a square matrix which only has non-zero elements on its diagonal and in its upper right triangular part does the job. We speak of an “upper triangular matrix“:
That such a matrix mixes vector components in the intended way follows directly from the definition of standard matrix multiplications. (Note: In Python/Numpy we talk about “matmul”-operations.)
Note that not all elements in the upper triangular part (aside the diagonal) are required to be different from zero. But at least one should be ≠ 0.
Not a full and neither a symmetric matrix
Now we come back to a point introduced already above: In principle we could allow for a coupling of two selected vector components in both logically possible ways. E.g., when we have an impact of the z- onto the x-component, why not also allow for an analogous impact of x- onto z at the same time? Maybe with a different linear factor?
Well, we then would get a full linear operation with possibly all n**2 elements having different values or we would get a symmetric matrices. A full generalization is not our objective. We want a special sub-case of a linear transformation. But why not allow for a symmetric matrix?
The reason for this will become clear when we discuss the decomposition and factorization of shear matrices in future posts. For the time being the following hint may help: The complexity of a linear operation can be measured by the minimum number of elementary operations required in a well chosen ECS. Can we find a coordinate system where the transformation reduces to just one elementary operation (translation, scaling, reflection, rotation)?
For a shearing transformation this would have to be a scaling operation as this kind of operation can at least potentially break rotational and planar symmetries.
Now we remember a result of linear algebra: Any symmetric matrix corresponds to an operation for wich we always can find a rotated ECS (at the center of an originally highly symmetric figure) in which the transformation of the figure reduces to a pure scaling operation.
For a shear operation we even want to exclude this kind of reduction: We shall not be able to find a ECS in which the operation just becomes a scaling. (A shearing shall in any coordinate system at least require a scaling and a rotation.) How can we achieve this? Well, we must not even allow for a symmetric matrix. For bodies which show original symmetries with respect to planes through its center this means that a shear operation destroys at least some of its planar symmetries whatever coordinate system we choose. Despite the fact that a shear operation can be inverted (see below)!
So, our elimination of some rotational and at least one planar symmetry in an originally highly symmetric body is reflected by the triangular form of the matrix. We avoid a 2-fold coupling between two selected coordinates at the same time. So when we have a matrix element mi,j, with j > i, we always set the corresponding element to zero: mj,i = 0.
This restricts the distortions we are going to get. Some surface elements are going to remain congruent and some point symmetries are kept up.
Why did we not use a lower triangular matrix?
Well, this is just a convention. Actually, the transposed matrix of an upper triangular one would also do the job – so we could also take matrices with non-zero elements only in the lower left triangle. But, for convenience, we will stick to matrices with non-zero elements in the upper right triangular part.
What about the diagonal elements of a shear matrix?
First of all note that not all elements on the diagonal of the matrix Msh should become zero – because then we would eliminate our original figure totally. But for a shear operation we do not want any of the vector components to disappear! In addition: As non-zero elements in the diagonal would reflect a simple scaling we do request that all of the diagonal matrix elements should be equal to 1 for a pure shear operation:
As the diagonal is fixed by elements mi,i(>i) = 1, we have reduced the number of free and independent (off-diagonal) parameters Nindsh(>i) of a pure shear matrix Msh from n**2 to:
So, in 2 dimensions instead of 4 parameters we set the diagonal elements to 1 and choose just 1 free off-diagonal parameter. In 3 dimensions we only have to set 3 instead of 6 off-diagonal parameters.
Basic properties of a shear matrix
A quick calculation shows: The determinant of a shear matrix is directly given by the product of its diagonal elements, and thus we have:
Therefore, a shear matrix is always invertible. This means its effects can be reverted – also in geometrical terms. The matrix also has full rank r = n.
The eigenspace and the eigenvalue(s) of a shear matrix Msh are also interesting. We can use a property of triangular matrices to get the eigenvalue(s):
The diagonal elements of a triangular matrix are its eigenvalues.
This in turn can be understood from analyzing the characteristic polynomial det(M – λI) = 0.
Thus: The one and only eigenvalue ev of Msh is 1.
\[ \pmb{ev}_{\operatorname{M}_{sh}} \, = \, 1
\]
The eigenvalues algebraic multiplicity in the characteristic polynom is n This does not yet tell us much about the geometrical multiplicity, i.e. the dimension of the eigenspace.
But all the n eigenvalues share the same eigenspace ES. ES is the kernel of the matrix (A – λI). Therefore, we can derive the eigenspace’s dimension by the dimension formula for this particular matri:
as the rank of the combined matrix on the right side is (n – 1).
You also see this understand this by looking at the 4-dim example matrix given above:
When you write down the equations you will find that only 1 variable can be chosen freely. So the kernel of the matrix (A – λI) is only 1-dimensional. Logically and geometrically, this is clear as any other coordinate value (≠ 0) beyond the first one mixes in contributions.
It is easy to prove that the eigenspace ES can be based upon the eigenvector e1.
Can Msh be diagonalized? Answer: No! From linear algebra we know that this would require n linearly independent eigenvectors. But we have just one! So:
Think a bit about the consequences:
An operation like that on the right side of the un-equation above would correspond to the representation of our shear matrix in a different (rotated) coordinate system. A diagonalization corresponds to an eigendecomposition; in geometrical terms a diagonal matrix represents a pure scaling operation. But, obviously, such a description of our shear operation in some (cleverly) selected ECS is not possible:
We cannot find a (translated and rotated) ECS in which a shear operation reduces to a scaling transformation. In any chosen (rotated) ECS there is always an additional second rotation involved which we cannot simply invert or get rid off!
We shall see this in more detail when we discuss decompositions. We simply cannot get rid of the fundamental asymmetry we have build into Msh by not allowing non-zero elements in the lower triangular part of the matrix! No change to a whatever selected coordinate system will help.
So, a shear operation really is a special symmetry breaking operation which cannot be reduced to just one elementary operation. In any ECS it requires at least a rotation and a scaling!
Summary:
A pure shear operation is introduced by some off-diagonal and non-zero element in the upper right triangular part of a unipotent matrix. All off-diagonal elements in the lower left triangular part are set to zero.
More illustrations from Blender
First some images for a cuboid that was more extremely deformed by shearing in x- and y-direction than the first one:
Now we come to an interesting example: We apply shearing in x- and y-direction to a sphere. We get something whose shape looks much more regular than that of a cuboid. We pick a unit sphere and apply to shearing operations in x- and y-direction:
The first image shows the original sphere from some point of view. The second image was taken from the same perspective, but now after the shearing. The resulting figure looks very regular – and it seems to have plane symmetries.
Another example with a bit of different lighting gives us:
Actually, we get an ellipsoid. We clearly can identify the two points which have a maximum absolute z-values whose tangent planes did not change tier orientation.
Ellipsoids (in 3D) are figures with 3 main axes and planar symmetries. The original fully rotational symmetry (first image of the series above) is obviously broken. However, we seem to have saved at least some planar symmetries. Hmmm …. Just when we thought we had understood that a shearing operation breaks original planar symmetries we have in our new example case kept some.
Why is this? What is so special about the shearing of spheres? Keep this question in mind.
Conclusion
Shearing transformations are a special class of linear and thus transformations. Shearing obviously can break some plane symmetries of originally highly symmetric bodies – as cubes. In contrast to other elementary affine operations no coordinate system can be found where the number of operations to reproduce the effects of a shearing can be reduced to one. In particular it is not possible to find an Euclidean coordinate system where it is just reduced to a (symmetry breaking) scaling with different factors in different coordinate directions.
Blender offers a simple graphical method to apply shearing to simple geometrical bodies. This allowed us to get an impression of the effects on cubes and spheres. Something that was a bit astonishing was the shearing effect on a unit spheres. It just created ellipsoids – again highly symmetric bodies WITH planar symmetries.