With the last one of the previous posts in this series
- More fun with veth, network namespaces, VLANs – IV – L2-segments, same IP-subnet, ARP and routes
- More fun with veth, network namespaces, VLANs – V – link two L2-segments of the same IP-subnet by a routing network namespace
- More fun with veth, network namespaces, VLANs – VI – veth subdevices for private 802.1q VLANs
we started to look at VLANs based on veths and Linux bridges. I presented multiple options to configure a veth endpoint in a network namespace for enabling communication with other namespaces via tagged Ethernet packets.
We saw that we can potentially start splitting network traffic already from within a multi-homed namespace which is connected to different VLAN-segments. However, a veth endpoint with multiple interfaces also poses a basic ambiguity problem for the direction of both ARP and ICMP requests into the right one of the various attached (V)LAN-segments. From the results of previous experiments we would assume that the Linux kernel solves this problem by following routes.
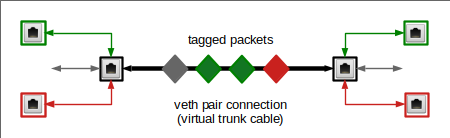
In this post we will study the most simple VLAN configuration one can think of: We connect two network namespaces directly with a veth based VLAN line. I.e. we use a veth connection to transmit tagged packets along it. As this would be a lit boring, we add some pepper to the scenario by allowing for untagged packets, too.
To achieve this we reduce “option 4” discussed in the last post to a one-armed solution: We allow for only one VLAN interface per veth endpoint (see a sketch of the scenario below). We start a series of experiments with assigning an IP to the veth’s main interface, only. The setting for the source validation kernel parameter rp_filter will be relaxed.
In the experiments of this post we focus on
- some claimed aspects regarding the role of the main trunk interface of a veth endpoint,
- the potential impact of routes on the ARP communication.
- the fact that working ARP does not mean working ICMP for a variety of different reasons.
Regarding the first point we will see that tagged packets just traverse the trunk interfaces on their way from and to the VLAN interface. Regarding route settings we will look at 36 possible variants. We will see that under the given conditions asymmetric route settings may or may not disable communication – already on the ARP level. But even if ARP works and even if we had symmetric routes in the namespaces, ICMP may not function. I will try to isolate the causes of positive and negative results for ARP and ICMP requests.
I recommend that readers who want to perform these experiments on their own to watch the system log in parallel.